

|
|
|
|
Les problèmes posés par cette approche directe sont selon nous de deux ordres. D'une part, les descriptions linguistiques pré-existantes doivent être entièrement retraduites dans le formalisme des TAG, c'est-à-dire, en pratique, entièrement refaites ; d'autre part, étant donnée la liaison forte entre la grammaire (les arbres TAG) et le lexique, toute modification de la grammaire, telle qu'un ajout ou une suppression d'arbre TAG entraîne une modification du lexique sous peine d'incohérence.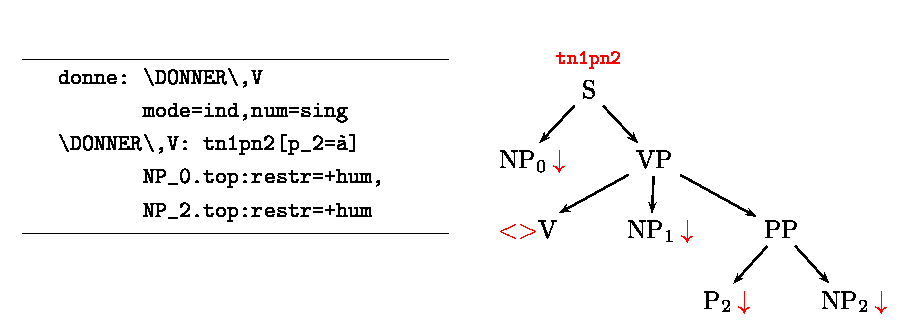
Figure 1 : Liens entre forme fléchie, lemme et arbre
|
|
|
|
|