L'analyseur syntaxique FRMG pour le français
Pour une phrase donnée, l'analyseur essaie de retourner la meilleure structure grammaticale. L'analyseur FRMG résulte de la compilation de la grammaire FRMG dans l'environnement DyaLog. C'est un analyseur robuste et à large couverture du français. Il est utilisé pour le traitement de très gros corpus, a participé aux campagnes d'évaluation EASy et Passage, et peut se comparer aux analyseurs statistiques sur leur corpus d'entraînement tout en restant stable hors domaine.
FRMG peut analyser une chaîne de mots et plus généralement un treillis de mots reflétant des ambiguïtés sur les mots et leur segmentation. Il calcule l'ensemble de toutes les analyses possibles, en s'appuyant sur des techniques d'analyse par charte (programmation dynamique). Une phase de désambiguïsation permet ensuite de sélectionner la meilleure analyse parmi l'ensemble généralement très grand de toutes les analyses. Cette phase de désambiguïsation peut faire appel à un modèle statistique appris sur un corpus annoté (treebank) pour de meilleures performances.
Pour la version de l'analyseur utilisable en ligne sur ce site, il est à noter qu'elle n'utilise pas un tel modèle statistique de désambiguïsation pour des raisons de temps de latence (le temps de chargement des modèles de quelques secondes est trop couteux pour une simple phrase et ne se justifie que lors du traitement de corpus). D'autre part, divers réglages (sur la segmentation en phrases/mots, sur la détection des entités nommées, sur l'utilisation de restrictions de sélection, ...) peuvent influer sur les performances et expliquer certaines différences entre la version en ligne et les résultats sur corpus.
FRMG ainsi que l'ensemble de la chaîne de traitement ALPAGE sont librement disponibles. Mais n'hésitez pas à nous contacter pour plus d'informations et de conseils si vous souhaitez utiliser nos outils pour vos applications, commerciales ou non.
Sorties FRMG
Nativement, l'analyseur FRMG produit des forêts partagées de dérivations TAG, indiquant l'ensemble des opérations TAG (substitution, adjonction, ...) effectuées, sur quel noeud et avec quel arbre. Ces forêts de dérivation sont ensuite converties en des forêts de dépendances. Intuitivement, l'idée (classique) est qu'une opération TAG consistant à appliquer un certain arbre β sur le noeud N d'un arbre α se traduit par une dépendance étiquetée N allant du mot ancre de α vers le mot ancre de β. Le principe est étendu pour matérialiser les opérations sur les noeuds lexicaux et sur les noeuds co-ancre. Néanmoins, ce schéma de conversion assume que tous les arbres élémentaires possèdent une ancre lexicale, ce qui n'est pas toujours le cas pour les arbres de FRMG. Dans ce cas, une pseudo-ancre lexicalement vide est utilisée comme tête ou cible des dépendances [1].
En pratique, les forêts partagées de dépendances sont représentées en XML pour le schéma DepXML. Ce même schéma est aussi utilisé après désambiguisation de la forêt. Il existe une visualisation graphique de ce format, utilisée par défaut sur ce wiki et également par le serveur de parseurs (parserd) et le nouveau shell pour FRMG (frmg_shell).
La forme graphique de DepXML permet essentiellement de visualiser
- des clusters (<cluster>) associés aux formes d'une phrase;
- des noeuds ( (<node>)) inclus dans les clusters précisant un lemme, une partie du discours (comme nc pour un nom ou v pour un verbe) et un arbre de la grammaire en cas d'ancrage par le mot en question. Les pseudo-ancres donne des noeuds lexicalement vides, mais possédant néanmoins comme catégorie syntaxique celle de la racine de l'arbre élémentaire associé;
- des arcs (<edge>) liant un noeud gouverneur à un noeud gouverné, associé par la couleur à un type d'opération TAG (substitution en bleu clair, adjonction en rouge avec ligne pointillée, co-ancrage ou lexical en violet, skip en vert), et portant un label. Ce label dénote en général une fonction syntaxique (comme sujet) dans le cas des opérations de substitution et de co-ancrage, et la catégorie syntaxique du gouverneur dans le cas des adjonctions.
La forme graphique de DepXML ne présente qu'une petite partie des informations fournies par ce format. En sus des éléments précédemment évoqués, le schéma DepXML fournit des informations:
- sur les constituants maximaux couverts par les arbres élémentaires, représentés par des balises <op>. Ainsi, le listing 1 fournit les informations sur le constituant nominal (catégorie N2) une pomme, à savoir féminin singulier 3ème personne non humain non temporel ...
- sur des hypertags (<hypertag>) fournissant, sous forme de structures de traits, les informations ayant permis d'ancrer un arbre de la grammaire par un mot de la phrase. Ces informations sont essentiellement pertinentes pour les verbes et fournissent la valence verbale de ceux-ci (pour les arguments arg0, arg1 et arg2), ainsi que sur la diathèse (diathesis), le contrôle (ctrsubj), .... Pour chaque argument est fourni la fonction grammaticale (function), le type (kind), la réalisation syntaxique (real), l'introducteur éventuel (pcas), l'extraction éventuelle (extracted). Le listing 2 montre ainsi l'hypertag associé au verbe ditransitif donner dans la phrase «il donne une pomme à Marie».
- sur des dérivations, non explicitement représentées mais en fait présentes au coeur des autres éléments, mais essentiellement importantes avant désambiguisation. Une dérivation groupe en effet un ensemble d'arcs pour un noeud gouverneur, définit un certain constituant (comme un Groupe Nominal N2), et est attaché à un hypertag (si l'arbre sous-jacent est ancré). Dualement, avant désambiguisation, un noeud peut être gouverneur pour plusieurs dérivations, un arc peut être utilisé pour plusieurs dérivations, et un constituant ou un hypertag peuvent être associés à plusieurs dérivations.
Il est évident que le schéma DepXML pourrait être grandement simplifié dans le cas de la représentation d'une seule analyse (au lieu d'une forêt partagée d'analyse). En particulier, les informations présentes dans <node>, <op> et <hypertag> pourraient être regroupées au sein de <node>. Les balises <deriv> pourraient aussi être éliminées ainsi que toute mention aux dérivations.
Listing 1 : <op> pour une pomme dans il donne une pomme à Marie
Listing 2 : <hypertag> pour donne dans il donne une pomme à Marie
Références
- É. Villemonte De La Clergerie, « Convertir des dérivations TAG en dépendances », in 17e Conférence sur le Traitement Automatique des Langues Naturelles - TALN 2010, Montreal, Canada, 2010.
Schémas et formats de sortie
L'analyseur FRMG produit par défaut des sorties en dépendances suivant le schéma DepXML, avec des dépendances reflétant directement les structures de la grammaire sous-jacente. Les sorties peuvent être affichées sous forme graphique, mais correspondent en fait à un format XML assez riche [1].
Néanmoins, les sorties peuvent aussi être converties vers d'autres schémas et formats, incluant:
- le schéma DepXML en format DepCONLL, un format tabulaire à la CONLL, légèrement étendu pour pouvoir représenter les deux niveaux des tokens et formes
|
Graph
|
Ce schéma DepConll peut bénéficier des simplifications apportées par l'option transform de l'analyseur qui cherche à faire disparaître les noeuds vides (non lexicalisés). Cette option est cependant encore instable !
|
Graph
|
- le schéma EASy/Passage (associé à un format XML), utilisé lors des campagnes d'évaluation EASy et Passage. Ce schéma s'appuie sur un mélange de 6 types de chunks et de 14 types de relations entre formes ou chunks (voir le manuel d'annotation utilisé dans le cadre du projet PASSAGE)
|
Graph
|
- le schéma Dépendance FTB, utilisé pour la représentation en dépendances du French Tree Bank (FTB), et représenté par le format tabulaire CONLL (plus d'information sur la page BONSAI d'ALPAGE)
|
Graph
|
- le schéma Dépendance Sequoia, une variante du schéma précédent, un peu plus précis dans les types de dépendances
- (nouveau) le schéma Universal Dependency, un format tabulaire (comme CONLL), sous sa forme instanciée pour le français. La conversion vers ce schéma est encore très expérimentale, en particulier du fait que la variante française n'est pas totalement spécifiée.
|
Graph
|
Références
- É. Villemonte De La Clergerie, « Convertir des dérivations TAG en dépendances », in 17e Conférence sur le Traitement Automatique des Langues Naturelles - TALN 2010, Montreal, Canada, 2010.
Évolutions du format de sortie
Pour essayer de rendre plus homogènes les configurations et les simplifier, un mécanisme de réécriture de graphe est en cours de développement. Les points principaux concernent:
- la suppression de la plupart des pseudo-noeuds lexicalement vides, en sélectionnant une tête plausible parmi les noeuds gouvernés par le pseudo-noeud. Par ordre de priorité décroissant, on choisit une tête accessible par un arc de substitution, ou un arc de co-ancrage, ou enfin un arc lexical.
- la re-routage de certains arcs pour mieux correspondre à des dépendances profondes. Par exemple, le transfert des sujets post-clitiques de l'auxiliaire vers le verbe principal, ou les cas d'extraction de génitif profond dans «il lui coupe les cheveux».
- le renommage de certains labels, en particulier pour les adjonctions. On peut ainsi envisager de renommer des fonctions syntaxiques en rôles thématiques (par exemple pour le passif).
- éventuellement, on peut envisager de passer d'arbres de dépendances en graphes de dépendances, en matérialisant, par exemple, des arcs pour le contrôle. Néanmoins, cette évolution amènerait à sortir du cadre du format DepXML.
|
Graphe transformé dans en riant, Marie lui a-t-elle coupé les cheveux ?
|
|
Graphe non transformé dans en riant, Marie lui a-t-elle coupé les cheveux ?
|
Pour l'instant, les transformations entraînent des problèmes avec l'interprétation DepXML, en particulier avec l'idée qu'une dérivation groupe des arcs partant d'un même gouverneur. Pour cette raison, la transformation n'est pas activée par défaut. Elle peut néanmoins être testé en cochant l'option 'transform' dans l'interface de visualisation.
Performances de FRMG
Nous donnons ici quelques éléments d'information sur les performances de FRMG, en terme de qualité sur divers corpus de test et métriques. Nous fournissons également des informations sur le taux de couverture par analyses complètes, sur divers styles de corpus. Enfin, même si ce n'est qu'indicatif, des informations sur les vitesses d'analyse, désambiguisation, et conversion
- [1] FRMG: évolutions d'un analyseur syntaxique TAG du français
- [2] Improving a symbolic parser through partially supervised learning
- [3] premiers résultats pour FRMG sur le corpus EASy
Améliorations grâce à l'utilisation de techniques de fouilles d'erreurs [4] sur les échecs d'analyse de gros corpus.
Le tableau suivant, issu de [2], donne, pour quelques corpus, quelques éléments d'information sur le taux de couverture par analyse complète (les autres phrases étant couverte par des analyses robustes). Le tableau fournit aussi les temps d'analyse moyens et médians.
| Corpus | #phrases | %analyse totale | temps moyen (s) | temps médian (s) |
|---|---|---|---|---|
| FTB train | 9881 | 95.9 | 1.04 | 0.26 |
| FTB dev | 1235 | 96.1 | 0.88 | 0.30 |
| FTB test | 1235 | 94.9 | 0.85 | 0.30 |
| Sequoia | 3204 | 95.1 | 1.53 | 0.17 |
| EasyDev | 3879 | 87.2 | 0.87 | 0.14 |
Le tableau suivant, issu de [2], donne des éléments d'évaluation de FRMG sur divers treebanks (FrenchTreeBank, Sequoia, EasyDev), pour divers schéma d'annotation (schéma FTB pour FTB et Sequoia; schéma Easy/Passage pour EasyDev) et avec 2 métriques (LAS pour le schéma FTB sans prise en compte des poncuations; F1-mesure sur les relations pour EasyDev). Les résultats, au moins sur le FTB, peuvent être comparés avec les ceux obtenus par des analyseurs syntaxiques (Berkeley, MALT, et MST) entraînés sur la partie FTB train (voir cette page pour plus d'information).
DYALOG-SR est un analyseur statistique par transitions (type MALT) s'appuyant sur des techniques de programmation dynamique et des faisceaux (beam). Comme FRMG, Il est lui-aussi implémenté au dessus du système DyALog. Une expérience récente a consisté à utiliser les sorties de FRMG comme traits de guidage pour DYALOG-SR [5], donnant d'excellents résultats sur le FTB, mais également sur le corpus SEQUOIA.
| French TreeBank (LAS) | Autres Corpus | |||||
|---|---|---|---|---|---|---|
| Analyseurs | Train | Dev | Test | Sequoia (LAS) | EasyDev (Passage) | |
| FRMG | base | 79.95 | 80.85 | 82.08 | 81.13 | 65.92 |
| +restr | 80.67 | 81.72 | 83.01 | 81.72 | 66.33 | |
| +tuning | 86.60 | 85.98 | 87.17 | 84.56 | 69.23 | |
| 2014/01 | 86.20 | 87.49 | 85.21 | |||
| 2015/03 | 86.76 | 87.95 | 86.41 | 70.81 | ||
| Autres Systèmes | Berkeley | 86.50 | 86.80 | |||
| MALT | 86.90 | 87.30 | ||||
| MST Parser | 87.50 | 88.20 | ||||
| dyalogs-sr | nu | 88.17 | 89.01 | 85.02 | ||
| guidé par FRMG | 89.02 | 90.25 | 87.14 | |||
Toujours dans [5], nous avons quelques résultats plus précis qui tendent à confirmer la stabilité de FRMG (et d'analyseurs couplés avec FRMG) sur des domaines autres que journalistiques (l'augmentation du taux d'erreurs est plus faible en absolu [delta(err)] et relatif [%delta(err)] pour FRMG). Après correction d'une mauvaise utilisation des traits morphosyntaxiques produits par FRMG sur Sequoia, nous fournissons également des résultats mis à jour (Sept. 2014).
| FRMG | DYALOG-SR | DYALOG-SR+FRMG | DYALOG-SR +FRMG (sept. 2014) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Corpus | #phrases | LAS | delta(err) | %delta | LAS | delta(err) | %delta | LAS | delta(err) | %delta | LAS | delta(err) | %delta |
| FTB Test | 1235 | 87.49 | 89.01 | 90.25 | 90.25 | ||||||||
| Europar | 561 | 87.97 | -0.5 | -3.8 | 87.00 | +2.0 | +18.2 | 88.94 | +1.3 | +13.4 | 89.15 | +1.1 | +11.3 |
| Annodis | 529 | 86.11 | +1.4 | +11.0 | 85.80 | +3.2 | +29.1 | 88.21 | +2.0 | +20.9 | 88.45 | +1.8 | +18.4 |
| Emea-fr Dev | 574 | 85.16 | +2.3 | +18.6 | 83.50 | +5.2 | +50.0 | 86.26 | +4.0 | +40.9 | 86.41 | +3.8 | +39.4 |
| Emea-fr Test | 544 | 84.67 | +2.8 | +22.5 | 85.01 | +4.0 | +36.3 | 86.87 | +3.4 | +34.7 | 87.77 | +2.5 | +25.4 |
| FrWiki | 996 | 83.53 | +4.0 | +31.7 | 84.39 | +4.6 | +41.9 | 86.23 | +4.0 | +41.2 | 86.94 | +3.3 | +33.9 |
Références
- É. de La Clergerie, Sagot, B., Nicolas, L., et Guénot, M. - L., « FRMG: évolutions d'un analyseur syntaxique TAG du français », in Journée de l'ATALA sur : Quels analyseurs syntaxiques pour le français ?, Paris, France, 2009.
- É. Villemonte De La Clergerie, « Improving a symbolic parser through partially supervised learning », in The 13th International Conference on Parsing Technologies (IWPT), Nara, Japon, 2013.
- P. Boullier, Clément, L., Sagot, B., et De La Clergerie, É. Villemonte, « « Simple comme EASy :-) » », in Proceedings of TALN'05 EASy Workshop (poster), Dourdan, France, 2005.
- B. Sagot et de La Clergerie, É., « Fouille d'erreurs sur des sorties d'analyseurs syntaxiques », Traitement Automatique des Langues, vol. 49, p. 41-60, 2008.
- É. Villemonte De La Clergerie, « Jouer avec des analyseurs syntaxiques », in TALN, Marseilles (France), 2014.
Installer la chaine Alpage
FRMG s'inscrit dans la chaine de traitement alpc développée par ALPAGE et installable via l'installeur alpi (Note: il est préférable d'utiliser la version d'alpi dockerisée). L'ensemble des logiciels de cette chaîne sont disponibles sous licence libre.
Alpc fonctionne sous les environnements Linux et MacOS. Elle est installable de deux façon, via gitlab en local, ou via docker dans un containeur
1) Installation via Docker - construction locale (voie recommandée)
Ce type d'installation nécessite d'avoir sur sa machine le logiciel docker qui fonctionne, et le daemon docker qui tourne en arrière plan. (Suivre les étapes d'installation de la documentation officielle selon votre OS).
Un docker est un containeur, qui (de façon très synthétique) permet de faire de la virtualisation légère, en se comportant comme une VM qui partage des ressources avec son hôte.
En construisant l'image docker, vous installez un containeur sous linux sur votre machine, et vous pourrez ensuite acceder à la chaine de traitement depuis ce containeur en ligne de commande.
Pour construire l'image Docker, suivez les instructions du Readme qui se trouve ici: https://gitlab.inria.fr/almanach/docker_webservices/, sur les informations d'installation de alpi.
2) Installation via Docker - récupération d'image sur le dockerhub (voie recommandée)
Ce type d'installation nécessite d'avoir sur sa machine le logiciel docker qui fonctionne, et le daemon docker qui tourne en arrière plan. (Suivre les étapes d'installation de la documentation officielle selon votre OS).
Les images Docker (attention, lourdes, environ 10Ga) sont directement récupérables sur le dockerhub de almanach, à l'adresse suivante: https://hub.docker.com/r/almanach/alpi/
La commande à effectuer est docker pull almanach/alpi:v01.
Sous Windows 10:
- Si l'installation ne démarre pas simplement avec "docker run almanach/alpi:v01", il est possible de la démarrer manuellement en effectuant la commande "docker run -it almanach/alpi:v01 sh" dans Windows Powershell. Ensuite, dans le container Docker, on doit exécuter les commandes "bash" suivi de "./alpi.pl". Note: la commande suivante "source /root/exportbuild/sbin/setenv.sh" ne fonctionne pas si on n'opère pas dans une console bash.
- Il est possible que le frmg_shell ne trouve pas le fichier CGI.pm. Un message d'erreur plutot long et contenant "Can't locate CGI.pm" apparait. Pour remédier à cette erreur, il faut trouver le fichier CGI.pm et le copier dans l'un des dossier mentionnés dans la liste @INC. La commande "cp ~/usr/local/share/perl/5.22.1/AppConfig/CGI.pm ~/usr/local/share.perl.5.22.1/" devrait résoudre le problème.
3) Installation locale
Pour obtenir la dernière version d'alpi sous gitlab, utiliser
git clone https://gitlab.inria.fr/almanach/alpi
la commande alpi se trouve ensuite dans le répertoire alpi/.
L'installation de Alpc à partir des sources (sous gitlab) est possible, mais la compilation des composants nécessite une machine relativement puissante, de la mémoire (2 à 4 Go), et de l'espace disque (au moins 10Go). L'utilisation de la chaîne requiert cependant moins de mémoire (en général).
Pour installer la chaîne avec alpi, depuis le dossier alpi:
perl ./alpi
Plus d'info, avec
perldoc ./alpi/alpi
ou
perl ./alpi/alpi --help
En cas de problème d'installation, ne pas hésiter à nous contacter, en joignant le fichier 'alpi.log' produit par alpi, et en fournissant des indications sur votre environnement (distribution, architecture, ...).
Certains packages peuvent être longs à installer (comme sxpipe, aleda et frmg). Pour éviter certaines recompilations en cas de problème ou de mise à jour, il est possible d'ignorer des packages avec skippkg
perl ./alpi/alpi --prefix=<where to install> --skippkg sxpipe --skippkg aleda
Utiliser l'analyseur FRMG
Une fois installée la chaîne de traitement Alpc, quatre modes d'utilisation sont disponibles, à savoir:
- utilisation directe en ligne de commande
- utilisation via le shell FRMG (
frmg_shell) - utilisation d'un serveur de parseur (
parserd) - utilisation d'un service Web (frmg_server.pl)
Mode ligne de commande
Ce mode est seulement présenté pour des raisons historiques et pour aider à l'intégration de FRMG.
Il s'appuie sur les commandes frmg_lexer et frmg_parser.
L'option '-loop' pour frmg_parser permet en fait de traiter un séquence de phrases. Il est donc possible de traiter le contenu d'un fichier
> cat myfile.txt | frmg_lexer | frmg_parser -loop -disamb -conll -multi
Par ailleurs, le lexer frmg_lexer accepte une chaîne de caractères en entrée et appelle le segmenteur sxpipe dessus. Mais il est également possible de passer au lexer le résultat d'une telle segmentation sous forme d'un DAG (ou treillis de mots).
> echo "il mange une pomme." | sxpipe | dag2udag | frmg_lexer | frmg_parser -loop -disamb -conll
Mode Shell
Le mode shell, avec la commande frmg_shell, est conseillé pour une première utilisation de l'analyseur FRMG.
La commande peut être aussi utilisée en mode batch
> echo ":xml:passage il mange une pomme." | ./frmg_shell --quiet > foo.xml
Elle peut également être utilisée pour traiter des corpus jouets. Par exemple, la commande suivante traite les phrases de mycorpus.txt pour produire des sorties en format CONLL (schéma FTB), stockées sous mycorpus/ à raison d'une phrase par fichier.
> echo "corpus mycorpus.txt mycorpus :conll" | frmg_shell --batch
ou (pour des sorties en format Passage/XML et mode robust) :
> echo "corpus mycorpus.txt mycorpus :passage:xml:robust" | frmg_shell --batch
Voici l'aide (à peu près à jour) des options de FRMG Shell
Mode Serveur
Ce mode, un peu plus compliqué à mettre en oeuvre, permet cependant le traitement de gros corpus sur des clusters de machines. Il repose sur l'utilisation du serveur parserd (qui devra tourner sur chaque noeud du cluster) et sur le contrôleur dispatch.pl qui a la charge d'envoyer les phrases du corpus aux noeuds, récupérer les résultats, et gérer les problèmes éventuels.
Le serveur parserd peut être lancé à l'aide de parserd_service, installé par alpi.
Le traitement d'un corpus peut alors être lancé, en précisant un certain nombre d'options dans un fichier de configuration (ou directement sur la ligne de commande)
Mode Service Web
Le package FRMG inclut le script frmg_server.pl qui permet de lancer un service Web sous Mojolicious, par exemple en lançant
morbo ./frmg_server.pl
Des réglages de configuration peuvent être fournis dans frmg_server.conf, (voir le modèle d'exemple frmg_server.conf.sample).
Il suffit ensuite d'ouvrir une fenêtre de navigateur sur l'adresse et port retourné lors du démarrage du service (par défaut: http://127.0.0.1:3000/process) . C'est ce genre de service WEB qui est utilisé par le visualisateur de sorties syntaxiques de ce site. Il est directement accessible ici. Dans l'interface WEB, le champ 'Options' peut être rempli par les mêmes options disponible pour le shell FRMG (mais séparées par des espaces plutôt que par ':').
NOTES: pour l'instant (Mars 2018), alpi m'installe pas de base tous les éléments nécessaires au service WEB. En particulier, il faut installer le module Perl DepXML
alpi --prefix=<prefix> --pkg=DepXML
La compilation de DepXML va requérir d'autres modules Perl (Devel::Declare, B::Hooks::EndOfScope), pouvant être installés via cpanm
FRMG Shell Help
FRMG shell commands
- quit : exit this shell (alias: q | bye )
- sentence <sent> : add <sent> to the sentence set and process it (alias: s| ' | .)
- load <file> : load a set of sentences from <file> (alias: open | o )
- save <file> : save the current sentence set into <file>
- list : list all sentences
- set <option> : set an option (see 'show options')
- show options (alias opt)
- help: shows this help (alias usage | h | ?)
- <empty line> : process the current sentence
- prev : process the previous sentence (alias -)
- prev <shift> : move back <shift> sentences and process (alias -<shift>)
- next : process the next sentence (alias +)
- next <shift> : move forward <shift> sentences and process (alias +<shift>)
- <sid> : process sentence <sid>
- (<sid>:<opts>)+ : process several sentences with local options (ex: 1:dep:nodis 1:dep:xml:o=s1.dep.xml 1:passage)
- dbdir <archive> : set <archive> as the current archive
- dbclose : close the current archive (alias clean)
- extract <format> <sid> <options> : display the content of the file for sentence <sid> in archive for <format>, if present. (alias <B>x</B>)
- !extract <sid> <options> : extract the sentence <sid> in archive. (alias !x)
- dagdir <dagdir> : set <dagdir>, to find DAGs
- !dag <sid> <options> : extract the DAG for sentence <sid>. (alias !d)
- corpus <corpus> <dest> :<options>: process <corpus> and save the results under <dest> directory
- % <shell cmd> : run shell command
This shell maintains an active sentence within a sentence set. New sentences may be added or loaded. The current set of sentences may be saved and searched.
Through the options (set and <sid>:<opts>), one may switch:
- the annotation scheme: dep, passage, French TreeBank conll, dep conll, or raw
- the representation format:
- xml (for passage and dep)
- html (for passage),
- graphical (for dep by default)
- svg (for dep) to be displayed with firefox (default) or with zgrviewer (option zgr)
- latex (for dep) -- require dot2tex
- the ambiguity: dis/nodis (for dep)
- parser options:
- ctag/nolctag (use of left corner relation)
- correct/nocorrect (correction mode when failure, on by default)
- robust (partial parsing when failure, off by default)
- disamb options: with dis_options="<opts>"
- debug:
- dyam (low level DyALog trace)
- follow (item histogram, require follow_exec.pl)
- flow redirect:
- o=<output> (save ouput in <output>)
- o=+<output> (append ouput to <output>)
- less or | (redirect to pager less)
frmg_shell may be used to examine the content of archives produced by dispatch.pl when processing (large) corpus.
frmg_shell may be used to process in batch mode (with option -batch) a set of commands provided in a file (-batch file) or on stdin (-batch -).
For more information about zgrviewer, see http://zvtm.sourceforge.net/zgrviewer.html
For more information about dot2tex, see http://www.fauskes.net/code/dot2tex/
Quelques applications de FRMG
Cette page recense quelques exemples d'utilisation de FRMG.
- Utilisation dans le cadre de l'ANR Rhapsodie pour préparer l'annotation syntaxique de corpus oraux, ainsi que dans le cadre de l'ANR ORFEO sur des corpus écrits et oraux.
- Utilisation dans le cadre d'une tâche d'extraction de citations dans des dépêches AFP [1]. Démo Sapiens, réalisée en 2010 sur des dépêches concernant la présidentielle de 2007 et ensuite complétée par des dépêches sur la réforme des retraites en 2010. L'idée est de pouvoir chercher qui a dit quoi sur diverses thématiques, en s'appuyant sur une analyse syntaxique avec FRMG de dépêches AFP, puis l'extraction avec DPath de verbes de communications avec ses divers arguments (le sujet/agent, l'objet/thème, l'audience, ...)
- Utilisation pour le traitement de toutes sortes de corpus, plus ou moins volumineux (comme Wikipedia ou Wikisource), et exploitation des sorties d'analyse syntaxique (en format Passage essentiellement) pour l'extraction de terminologies et la constitution de réseaux de mots (en s'appuyant sur l'hypothèse distributionnelle de Harris) [2] [3] (voir des exemples sur http://alpage.inria.fr/~clerger/wnet/wnet.html et sous l'interface Libellex). Pour l'interface Libellex, on peut se connecter avec l'identifiant guest et passe guest pour ensuite choisir un réseau (par exemple allsement). Pour voir l'ensemble des arcs, cochez "related" dans la tuiles "Options ...".
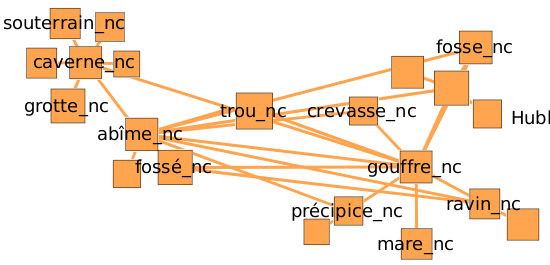
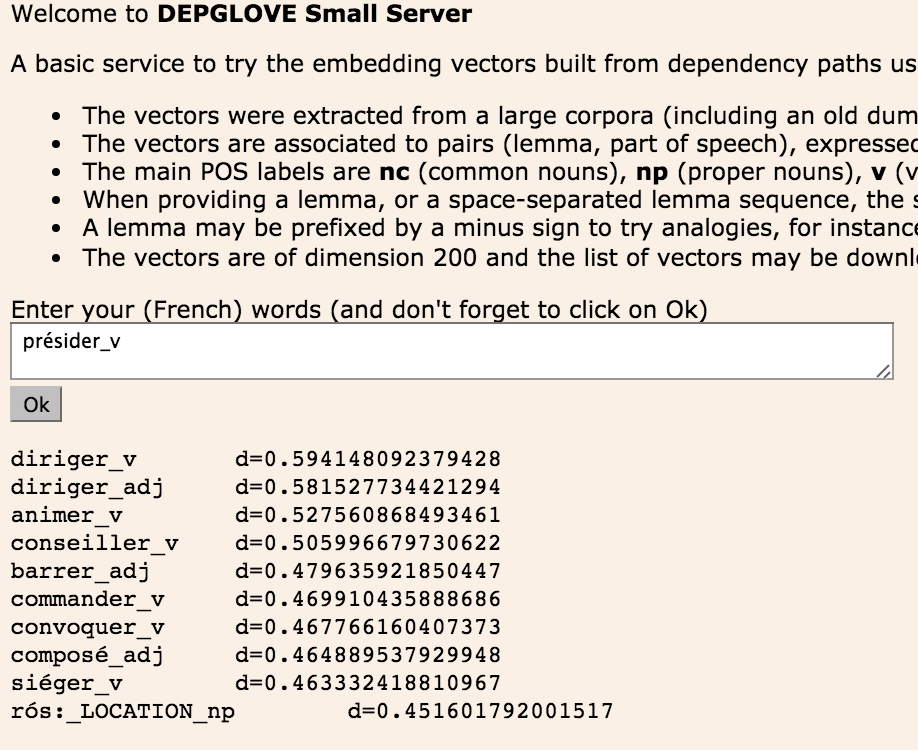
- (Sept 2016) Dans la continuité des travaux précédents autour de l'hypothèse distributionnelles, les sorties de FRMG sur gros corpus ont été utilisées pour associer aux mots des vecteurs denses (word embeddings) de dimension entre 100 et 200. L'algorithme utilisé baptisé DepGlove est une variante maison de Glove, lui-même un concurrent du désormais célèbre Word2Vec. La particularité de DepGlove est de s'appuyer sur des chemins syntaxiques issus des formats DepXML ou Passage plutôt que la simple proximité dans la phrase (approche sac-de-mot). Une interface très basique permet de tester ces vecteurs et aussi de les récupérer (au format word2vec). Les vecteurs peuvent aussi être récupérés directement ici.
Références
- É. de La Clergerie, Sagot, B., Stern, R., Denis, P., Recourcé, G., et Mignot, V., « Extracting and Visualizing Quotations from News Wires », in LTC 2009 - 4th Language and Technology Conference, Poznań, Pologne, 2009.
- M. Morardo et De La Clergerie, É. Villemonte, « Vers un environnement de production et de validation de ressources lexicales sémantiques », in Atelier TALN 2013 SemDIS, Les Sables d'Olonne, France, 2013.
- M. Morardo et De La Clergerie, É. Villemonte, « Towards an environment for the production and the validation of lexical semantic resources », in The 9th edition of the Language Resources and Evaluation Conference (LREC), Reykjavik, Islande, 2014.