Playing with the parser
Recipes for the impatients
The parsing interface
The best way to play with FRMG is to use the parsing interface available on this wiki, also accessible in the left side panel. The Schema menu allows you to select an ouput schema. The other options activate extra functionalities, such as returning partial parses when no complete parse can be found for a sentence (robust mode). Some of these functionalities are still experimental, like the advanced mode for dealing with ellipses in coordinations, renaming some edges, or removing some edges and nodes (essentially the nodes corresponding to non-lexicalized trees represented by empty pseudo-anchors).
More information about using the interface may be found here. In particular, it is possible to switch to full-screen or to fold a tree to focus on the interesting parts. A parse can also be edited, either by exploring parse alternatives (just click on a target node to see all potential incoming dependency edges) or even by adding or deleting edges. Finally, the edges may be highlighted, an interesting functionality to point to errors (in a discussion) or to pinpoint the key characteristics of a syntactic phenomena (its signature).
Actually, the signatures are used to propose a list of related pages (top right side panel) where are discussed syntactic phenomena. This mapping is still very experimental and far from being perfect !
A sentence parse may also be saved and added to a basket. It may also be proposed as a sentence of the day (the final decision being mine !). And as seen, sentence parses can easily be inserted in wiki pages to illustrate syntactic phenomena (especially when highlighting its signature) or to pinpoints weaknesses in FRMG analysis. Finally, the parses come with leftmost up and down hands that may be used to provide your opinion about their correctness.
Finally, please note that the parses returned through the interface are not always the best ones one may get with FRMG. Indeed, for efficiency reason and because the parser is started from scratch for each sentence, the use of statistical models for the disambiguation is not activated (the latency time of a few seconds for loading them being too high). However, the corpus processing service uses such models.
The parsing service
The parsing interface actually calls a cruder but more complete parsing service available here. Its interface is less sophisticated but actually accepts a larger set of options and provides a greater variety of output views.
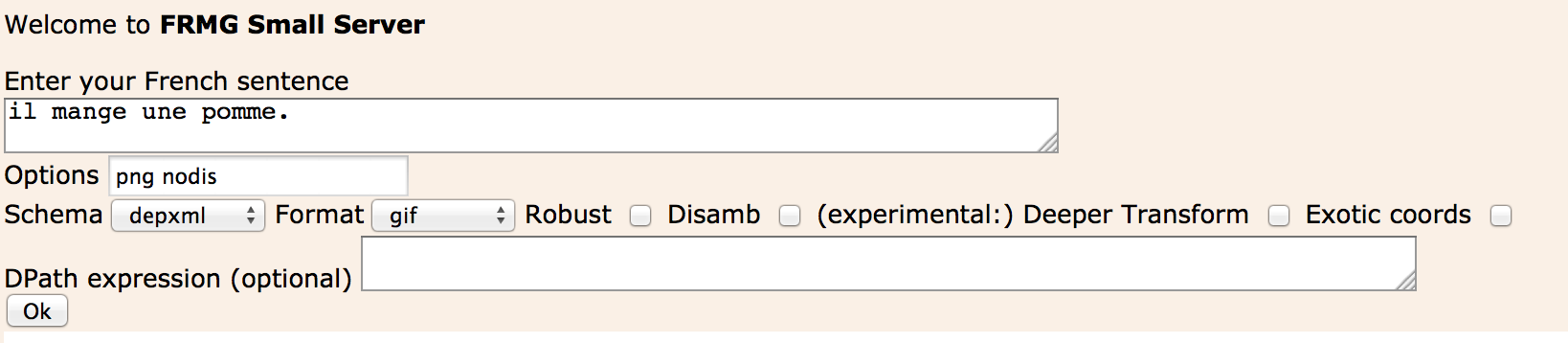
The options should be provided in the Option textfield (the checkboxes are actually not active !)
- png: to get a png image (please note that for an image as output, this option is mandatory)
- nodis: to get the full dependency forest
- xml: to get the xml file with all information
- token: to show the output of the tokenizer (SxPipe)
- lexer: to show the output of the lexer (after consultation of the Lefff lexicon)
- follow: to get an idea of the number of computation tried during parsing at each word of the sentence
- robust: to get partial parses in case of failure to get a complet one for a sentence
- conll, depconll, udep, passage: several output annotation schema
- and many others !
The corpus processing service
FRMG Wiki also provides a service to process small corpora (less than one million words). Il allows to upload a corpus and get the parse results (as an archive) when parsed. It also possible to consult the results online and to query them using the DPath query language, inspired by XPath (with its navigation axes).
Recipes for the geeks
For the courageous geeks, it is possible to install the full processing chain developed by the ALPAGE team, including FRMG (but also SxPipe, Lefff, Aleda, mgcomp, DyALog, Syntax, mgtools, tag_utils, forest_utils, ... ![]() ).
).
All needed packages are freely available under open-source licenses. They may be fetched from INRIA GForge and compiled under Linux and Mac OS environments. The process is however largely automated with the help of the alpi installer, a Perl script that does the job of fetching and compiling the Alpage packages and the missing dependent packages (mostly Perl ones, but also libxml or sqlite).
The alpi script may be found here (Note:it is strongly advised to use the version that is available under SVN, the released one being outdated !). Please note that the compilation of some components (in particular FRMG) requires a relatively powerful computer, with RAM (2 to 4 Go) and disk (at least 10Go). Fortunately, the run time requirements for using the chain are more reasonable !
To install the chain with alpi, fetching the sources from the SVN repositories:
perl ./alpi --svn=anonymous --prefix=<where to install>
For more info, use
perldoc ./alpi
or
perl ./alpi --help
In case of problem, please contact me by mail, attaching the file 'alpi.log' produced by alpi, and providing information about your system, environment, ...
To have more information about using the chain once installed, please have a look here (in French). In particular, a small shell is available, proposing options similar to those of the parser service but completed with an history mechanism.
- Version imprimable
- Connectez-vous ou inscrivez-vous pour publier un commentaire