From (shared) forests to dependency trees and beyond
Shared forests, derivations and dependencies ?
In our first examples with TAGs, we have seen that trees may be combined through substitution and adjoining to get complete parse trees.
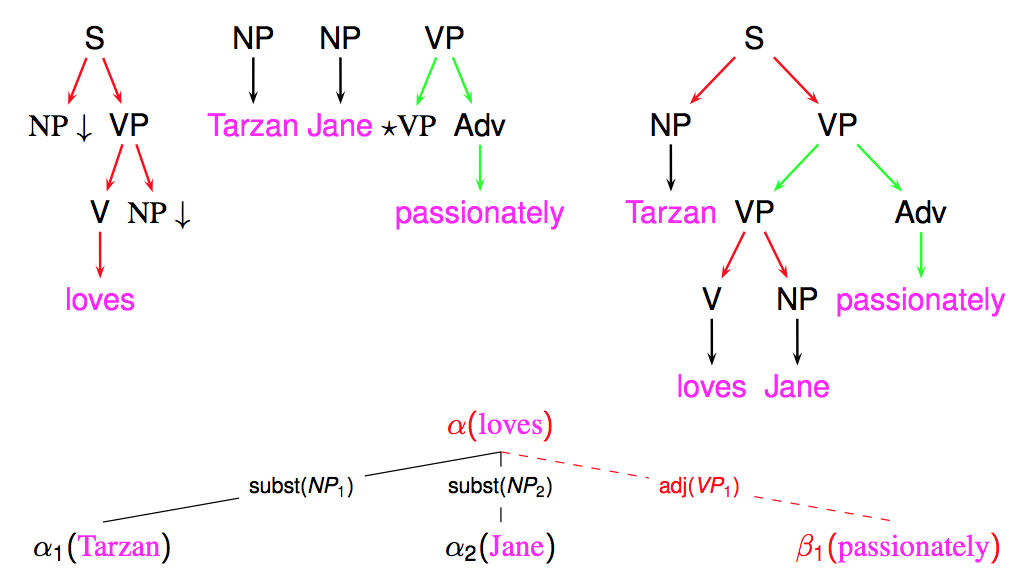
These parse trees may be useful, but what is actually more useful are derivation trees (my opinion, but it may be discussed) ! A derivation tree keeps trace of all operations (substitution or adjoining) needed to build the parse tree, with the indication of the nodes where the operations took place, and of the elementary trees that were used.
The following figure shows an example of a derivation tree
<
p class="align-center">
The interest of derivation tree partly stems from the observation that they better reflect the underlying semantic structure (than parse trees), in particular by relating a predicate (such as a verb) with its arguments (through substitution edges).
A derivation tree can also be more straightforwardly converted into a dependency tree, by establishing a dependency between the anchors of the trees that are the source and target of each derivation edge. For instance, in the previous example, a dependency edge will be established between loves and Tarzan. In the case of non-anchored trees (present in FRMG), a pseudo empty anchor will be positioned in the sentence (on the left-side of the span covered by the tree) and used as source or target of the dependency.
In practice, the FRMG parsers computes all possible parses for a sentence. But rather to enumerate all possible derivation trees, it may return them under the form of a much much more compact shared derivation forest ! The basic idea of shared forests is that not only subtrees may be shared but also contexts, leading to AND-OR graphs.
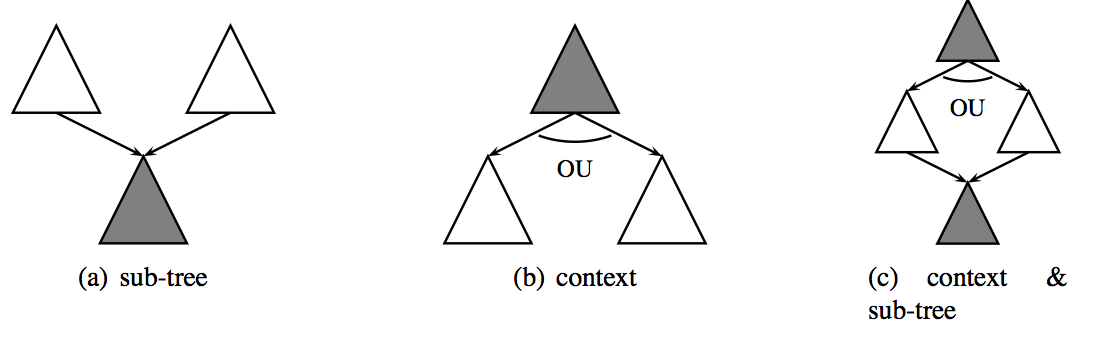
However such AND-OR graphs can also be represented under the form of context-free grammars (an important theoretical result), with terminals and non-terminals decorated with spans over the sentence. Such derivation forests as CFGs may be returned by frmg_parser with the option -forest (inherited from DyALog). However, nobody (but I) really wants to have a look at them !
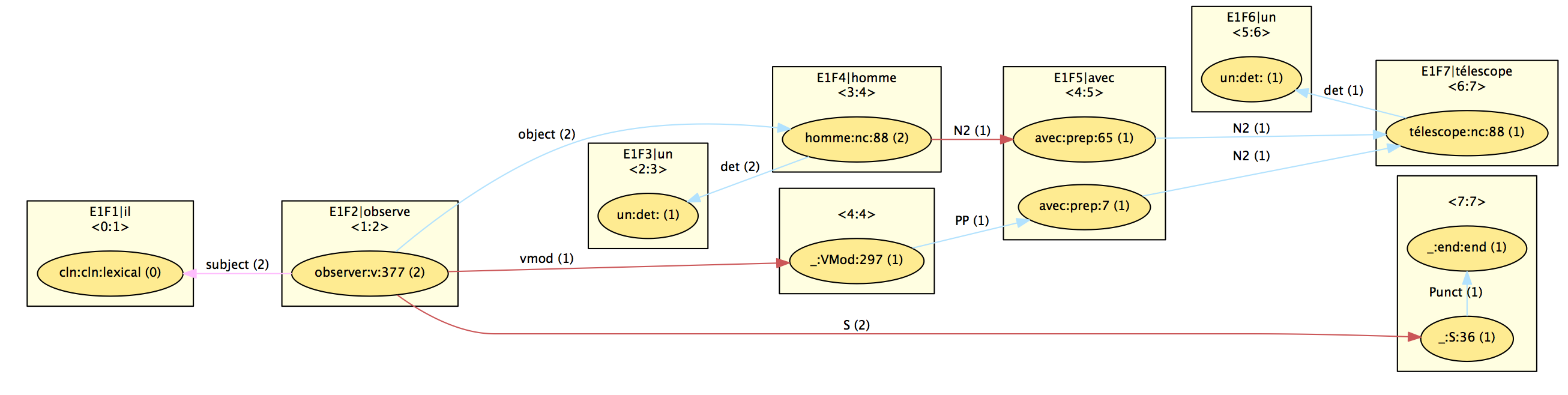
A first step is to get a shared dependency forest, following the principles mentioned above (to convert a derivation tree into a dependency tree) but keeping as much as possible sharing. The results is the base for the native DepXML representation of the output of FRMG with the following XML elements (some of them being visible in the graphical view derived from DepXML as illustrated below on the famous "he observes a man with a telescope" with prepositional attachment ambiguities):
The DepXML annotation schema relies on
- clusters, (rectangle) used to list the words of the sentence (possibly with some redundancy because of segmentation/tokenization ambiguities provided by SxPipe)
- nodes, (ellipses) associated to a cluster, a part of speech, a lemma, and generally the tree that is anchored by the node. Because of ambiguities, several nodes may be associated to a same cluster (for instance "avec")
- edges (lines) linking a source node with a target node and with a label and a TAG operation type (substitution, adjoining, ...)
- deriv (not visible) : because of ambiguities, a given edge may actually be used by several of the alternative derivations associated with the source node. For instance, the subject and object edges are used by the 2 possible derivations anchored on "observe", while the vmod edge is used by only one of them.
- op (not visible) : they correspond to the constituent covered by an elementary tree and are characterized by a span, a root syntactic category (such as S, or N2), and a set of derivations
- hypertag (not visible) : they provide the hypertag feature structure used to anchor a tree (op) by an anchor (node). Because of ambiguities, a same hypertag may be associated to several derivations.
Disambiguation with heuristic rules
Disambiguation is primarily achieved thanks to a set of around 230 heuristic disambiguation rules assigning weight to edges. These rules essentially consult information related to a single edge, such as its label, type, source and target nodes (part-of-speech, lexical information, morpho-syntactic features, ...). Some rules may also consult information about adjacent edges (incoming ones to the source node or outgoing ones from the target node). A very small number of rules may also consult alternative edges to the one being evaluated.
For instance, the following rule favors the modal verb edges:
There also exist a very few number of 14 "regional cost rules" that work for a node N and a set of edges leaving N that form a derivation. One of these rules is used for coordinations to favor coordinations between similar coordinated parts. However, because the number of derivations may be very high (due to ambiguities), the number of regional cost rules is kept very small and they are only used on a subset of the most promising derivations.
Disambiguation computes all edge costs, some regional costs, and return the best dependency tree, using a dynamic programming algorithm.
In its initial (and default) setting, the weights associated to the rules were manually set and already provided a good accuracy (over 80% LAS accuracy on the French Tree Banks). Since then, machine learning techniques have been designed to learn these weights from the French TreeBank, boosting the accuracy around 87%. More details here !
Converting to various output schema/formats
As already mentioned, the native output schema for FRMG is the DepXML one, that may be used both for representing a whole shared dependency forest or a single dependency tree (which partly explains some of the complexity of this schema). It also tries to provide all pertinent information (such as hypertags and morpho-syntactic feature structures).
However, over the years, it became necessary to implement converters to other annotation schema:
- The first of them was the Passage schema that was needed to perform evaluations of FRMG during the EASy and Passage parsing evaluation campaigns for French.
- The second one was the FTB/Conll schema used to represent the dependency version of the French TreeBank (whose original version is annotated by constituent). This second schema allowed us to evaluate FRMG against the dependency version of the FTB and also led to the improvement of the disambiguation process of FRMG. Several variants of this schema have been implemented to cover the variants used for the SEQUOIA Treebank (spmrl variant) and the French Question Bank (fqb).
- More recently, a third converter was added for the French Universal Dependency annotation scheme, to conduct evaluations on the on-going project of UD French TreeBank.
At this point, it is worth mentioning that we have here a clear distinction between symbolic grammars and data-driven approaches. A symbolic grammar is supposed to deliver the parses in relation with its structures and underlying grammatical formalisms. Conversions are needed when dealing with another schema. On the other hand, data-driven approaches learns the schema from the data, and may learn another parser for another schema from another treebank. There is generally no need for conversion.
Conversion between syntactic schema may seem as relatively simple problem. This is not the case !
Even between dependency-based schema, the source and target schema generally differ on their set of dependency labels (easy), part-of-speech (more or less easy), handling of MWEs (difficult), and notion of heads (even more difficult). The difference on the notion of heads means that local modifications of the input dependency structure may not sufficient and that modifications may propagate far away in a sentence.
For instance, in FRMG, modal verbs are adjoined on the main verb, while they are considered as main verbs for FTB and UD, as shown on the following exemples.
|
DepXML view
|
|
FTB/Conll view
|
Another example is provided by the clefted constructions that are seen as a kind of relative construction for FTB/Conll
|
DepXML view
|
|
FTB/Conll view
|
The converters for FRMG are essentially a set of transformation rules. However, to avoid a multiplication of the number of such rules, a notion of propagation has progressively emerged leading to 2-phase rewriting system. The first phase consists into applying basic transformation rules, some of them creating edges with "propagation" constraints. For instance, an edge with an up-constraint will reroot the edges leaving from its target node at the level of its source node.
Getting deeper representations
Thanks to adjoining and the extended domain of locality of TAGs, FRMG is able to provide relatively deep analysis, in particular through long distance dependencies.
However, in the perspective of information extraction application where one needs to know all the actants involved in an event, it is immediate to realize that some of these actants are hidden and not immediately available. Recently, we realized that some information could be added at the level of the meta-grammar to more easily retrieve and materialize these "deeper" dependencies as secondary edges.
The following sentence shows several instances of such deeper dependencies (in gray) for controlling verbs and coordinations, with "lui" being the hidden subject of both "partir" and "revenir".
|
Deep dependencies
|
These deeper dependencies are still experimental. As explored for the converter, they require some notion of propagation to be applied during the conversion of the shared derivation forest into a shared dependency forest, propagation that it not yet complete and correct ! Also, the cost of applying the propagation in a forest is still relatively high.
But nevertheless, it is interesting to observe the effect of propagation on the following complex and somewhat artificial sentence:
|
Graph
|
Another experimental mechanism has been also deployed at the level of the parser to deal with some specific cases of ellipses of coordinations. In these cases, a deeper representation would like to materialize the shared elements and the ellipsed ones. In the parsing interface, this mechanism may be activated by checking the option box "Coordinations (expérimental)"
Checking the option, we get the following parse, where we observe that the ellipses of both "veut" and "donner" are retrieved with their own set of arguments.
|
Ellipses verbe+modal dans Paul veut donner une pomme à Jean et son ami une poire à François.
|
More examples may be found here.
- Version imprimable
- Connectez-vous ou inscrivez-vous pour publier un commentaire