Révisions
The development of FRMG was initiated in 2004 in order to participate to EASy, the first parsing evaluation campaign for French. Developing a first working version for the campaign took less than 6 months, illustrating the interest of meta-grammars to quickly design relatively large coverage grammars.
However, the last 10 years have been busy improving FRMG and have led to the development of several auxiliary tools to monitor, debug, evaluate, ..., in other word, the necessary duties of real-life grammar engineering.
Actually, improving a grammar like FRMG means to work along the 3 following axes:
- improving the coverage, with the description of more and more syntactic phenomena and ways to deal with errors in sentences (robustness)
- improving the accuracy of the parses
- improving the efficiency, ie the speed of parsing but also of the other phases (forest extraction, disambiguation, conversions)
Unfortunately, these 3 axes are not easily conciliable ! Increasing the coverage tends to degrade the efficiency and may also lead to a degradation of accuracy: a new badly constrained rare syntactic phenomena may overtake some more common phenomena. Improving efficiency may require to prune search space and loose good parses. Improving accuracy may require more disambiguation rules, more discriminative features, leading to longer disambiguation times.
Coverage
The normal way to improve coverage is of course to add new classes in the metagrammar to cover missing syntactic phenomena. This process may be helped by parsing large corpora and looking at "failed sentences", ie sentences that couldn't be parsed. When modifying the grammar, it is also important to try test suites and to re-parse corpora to check that sentences that were successful remain successful.
Actually, there may be many reasons for a sentence to fail, not necessarily because of missing syntactic phenomena. It may also comes from missing or bad lexical entries, new words, badly recognized named entities, exotic typography, spelling errors, ....
In order to better identify the source of errors, we developed error mining techniques. The algorithm is essentially a variant of EM (expectation maximization) that tries to find suspect words that tend to occur more often than expected in failed sentences and in presence of words that tend to occur in successful sentences. Error mining proved to be very useful to detect lexical issues, but also to detect exotic typographic conventions and even syntactic issues. Actually, the idea of error mining may be extended to go beyond words, by working at the level of part-of-speech, n-grams, ...
Another way to improve coverage in the robust mode of FRMG that may be used to return a set of partial parses covering a sentence that has no full parse. While interesting, the resulting partial parses tend to have a lower accuracy than the full one, and the robust mode remain a default mode when everything else fails !
More recently, a correction mode has been implemented to be tried before the robust mode. The motivation is the observation that many failures actually arises from "errors" in the sentences, such as missing coma, participle used in place of infinitive (and conversely), agreement mismatch between a subject and its verbs, .... So a set of rules have been added and the correction mechanisms detect if some of these rules may apply, proposes a correction (for instance, underspecifying the mood of a verb), and re-run parsing (but keeping trace of what has been already computed). The correction mechanism is a way to get full parses even in presence of errors. As a side effect, the mechanism also provides a way to deliver feedback to an user about its errors.
|
Several corrections applied on this sentence
|
Accuracy
Improving the set of disambiguation rules
Tuning the weights of the disambiguation rules on the French TreeBank
Injecting knowledge learned from the parsing large corpora, using the distributional hypothesis (more info here). Using clustering information (Brown clusters) and, to be tried, word embeddings (also extracted from the parses on large corpora, available here).
Efficiency (speed)
Many many ideas have been explored, most of them being failures !
We list here some of most successful ones (it would be really difficult to describe all of them into details !)
Moving to an hybrid TIG/TAG grammar
Using a left-corner relation
Using lexicalization to filter the grammar
Using restriction constraints
Restricting the search space with guiding information
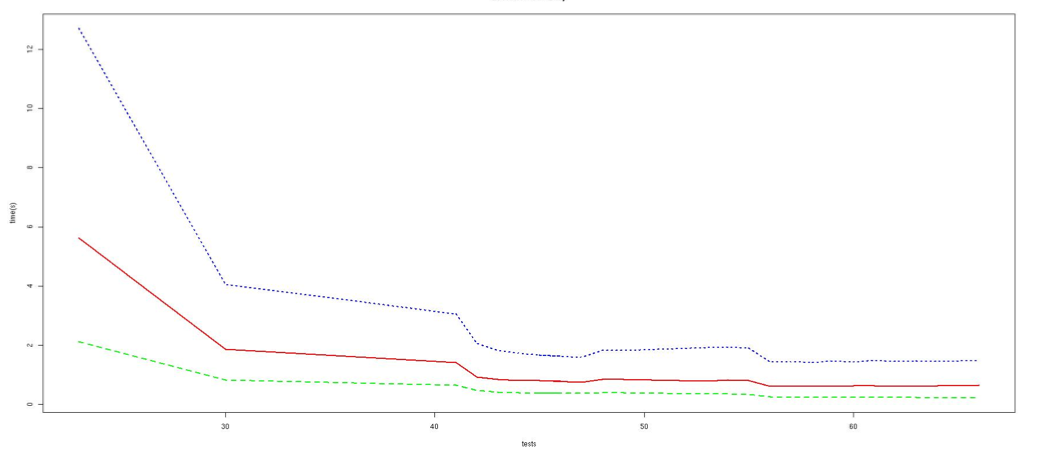
Looking at performances
| Corpus | #sentences | %coverage | avg time (s) | median time (s) |
|---|---|---|---|---|
| FTB train | 9881 | 95.9 | 1.04 | 0.26 |
| FTB dev | 1235 | 96.1 | 0.88 | 0.30 |
| FTB test | 1235 | 94.9 | 0.85 | 0.30 |
| Sequoia | 3204 | 95.1 | 1.53 | 0.17 |
| EasyDev | 3879 | 87.2 | 0.87 | 0.14 |
| French TreeBank (LAS, no punct) | Other Corpora | |||||
|---|---|---|---|---|---|---|
| Parsers | Train | Dev | Test | Sequoia (LAS) | EasyDev (Passage) | |
| FRMG | base | 79.95 | 80.85 | 82.08 | 81.13 | 65.92 |
| +restr | 80.67 | 81.72 | 83.01 | 81.72 | 66.33 | |
| +tuning | 86.60 | 85.98 | 87.17 | 84.56 | 69.23 | |
| 2014/01 | 86.20 | 87.49 | 85.21 | |||
| 2015/03 | 86.76 | 87.95 | 86.41 | 70.81 | ||
| Other Systems | Berkeley | 86.50 | 86.80 | |||
| MALT | 86.90 | 87.30 | ||||
| MST Parser | 87.50 | 88.20 | ||||
| dyalogs-sr | nu | 88.17 | 89.01 | 85.02 | ||
| guidé par FRMG | 89.02 | 90.25 | 87.14 | |||
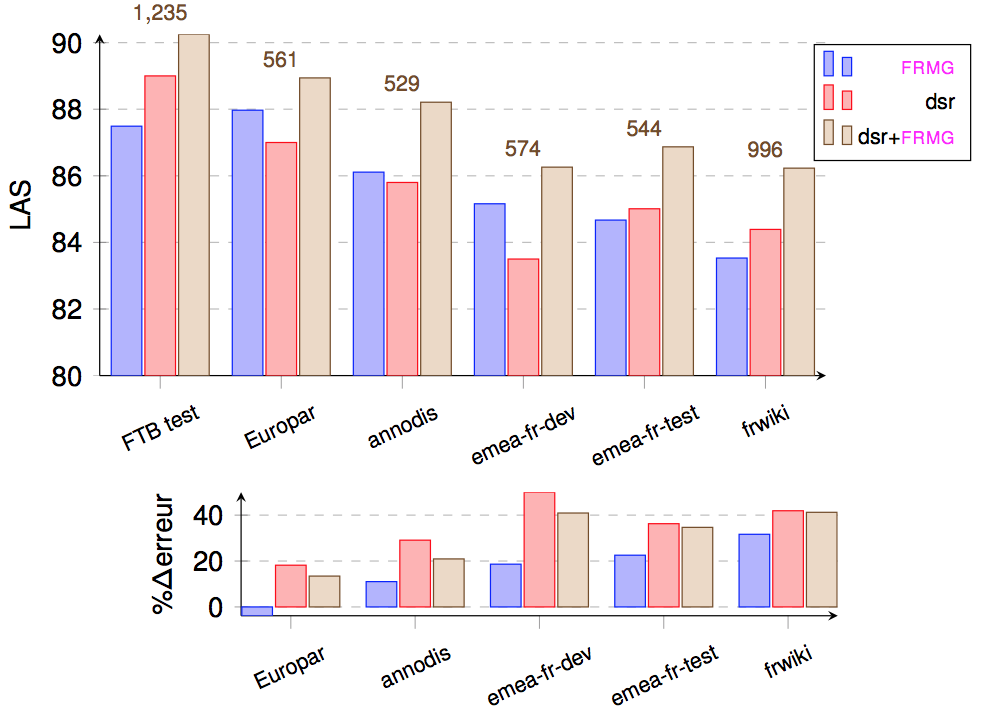
We have also conducted evaluation of FRMG, DyALog-SR, and the combined one on the SEQUOIA TreeBank.
| FRMG | DYALOG-SR | DYALOG-SR+FRMG | DYALOG-SR +FRMG (sept. 2014) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Corpus | #sentence | LAS | delta(err) | %delta | LAS | delta(err) | %delta | LAS | delta(err) | %delta | LAS | delta(err) | %delta |
| FTB Test | 1235 | 87.49 | 89.01 | 90.25 | 90.25 | ||||||||
| Europar | 561 | 87.97 | -0.5 | -3.8 | 87.00 | +2.0 | +18.2 | 88.94 | +1.3 | +13.4 | 89.15 | +1.1 | +11.3 |
| Annodis | 529 | 86.11 | +1.4 | +11.0 | 85.80 | +3.2 | +29.1 | 88.21 | +2.0 | +20.9 | 88.45 | +1.8 | +18.4 |
| Emea-fr Dev | 574 | 85.16 | +2.3 | +18.6 | 83.50 | +5.2 | +50.0 | 86.26 | +4.0 | +40.9 | 86.41 | +3.8 | +39.4 |
| Emea-fr Test | 544 | 84.67 | +2.8 | +22.5 | 85.01 | +4.0 | +36.3 | 86.87 | +3.4 | +34.7 | 87.77 | +2.5 | +25.4 |
| FrWiki | 996 | 83.53 | +4.0 | +31.7 | 84.39 | +4.6 | +41.9 | 86.23 | +4.0 | +41.2 | 86.94 | +3.3 | +33.9 |
- Version imprimable
- Connectez-vous ou inscrivez-vous pour publier un commentaire