Révisions
In our first examples with TAGs, we have seen that trees may be combined through substitution and adjoining to get complete parse trees.
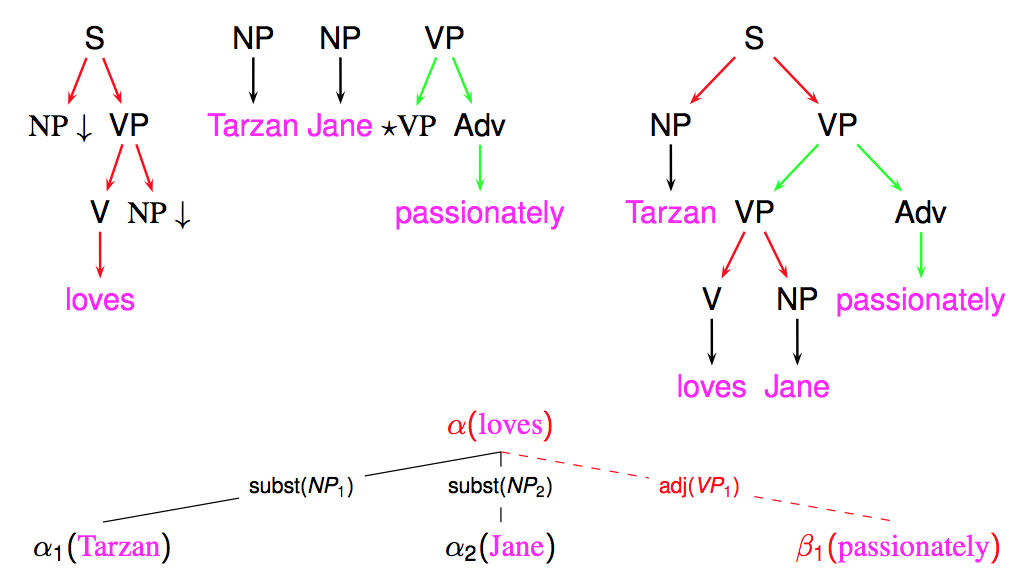
These parse trees may be useful, but what is actually more useful are derivation trees (my opinion, but it may be discussed) ! A derivation tree keeps trace of all operations (substitution or adjoining), on which nodes these operations took place, and which elementary tree were used.
The following figure shows an example of such derivation tree
<
p class="align-center">
The interest of derivation tree partly stems from the observation that they better reflect an underlying semantic structure, in particular by relating a predicate (such as a verb) with its arguments (through substitution edges).
A derivation tree can also more directly converted into a dependency tree, by establishing a dependency between the anchors of the trees that are the source and target of each derivation edge. For instance, in the previous example, a dependency edge will be established between loves and Tarzan. In the case of non-anchored trees (present in FRMG), a pseudo empty anchor will be positioned in the sentence (on the left-side of the span covered by the tree) and used as source or target of the dependency.
In practice, the FRMG parsers computes all possible parses for a sentences. But rather to return all possible derivation trees, it may return them under the form of a shared derivation forest, generally much much more compact ! The basic idea of shared forests is that subtrees may be shared but also contexts, leading to AND-OR trees.
However such AND-OR trees can also be represented under the form of a context-free grammars, with terminal and non-terminal decorated with spans over the sentence.
- Version imprimable
- Connectez-vous ou inscrivez-vous pour publier un commentaire