Révisions
Shared forests, derivations and dependencies ?
In our first examples with TAGs, we have seen that trees may be combined through substitution and adjoining to get complete parse trees.
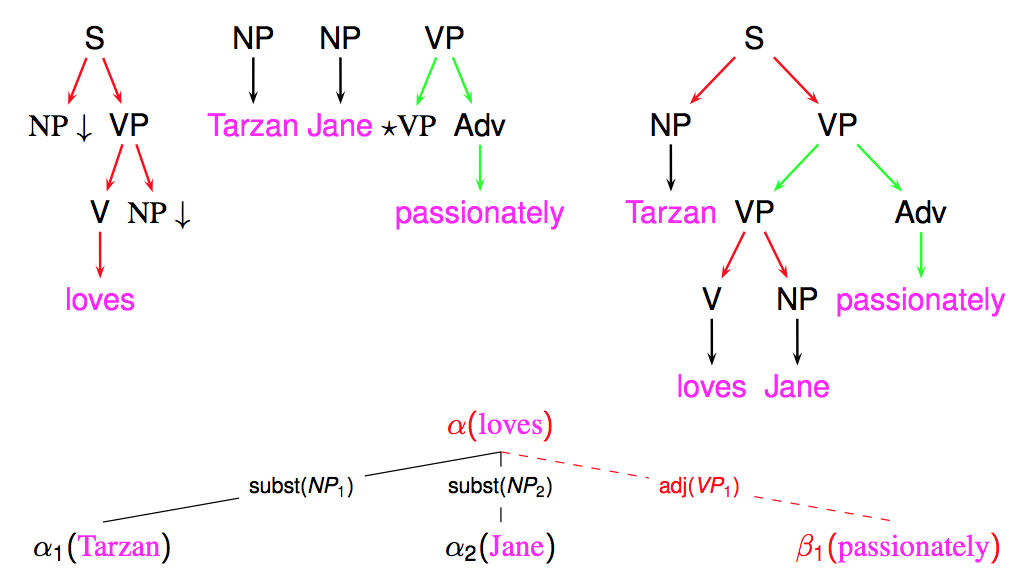
These parse trees may be useful, but what is actually more useful are derivation trees (my opinion, but it may be discussed) ! A derivation tree keeps trace of all operations (substitution or adjoining) need to get the parse tree, with indication of the nodes these operations took place, and of the elementary trees that were used.
The following figure shows an example of such derivation tree
<
p class="align-center">
The interest of derivation tree partly stems from the observation that they better reflect the underlying semantic structure, in particular by relating a predicate (such as a verb) with its arguments (through substitution edges).
A derivation tree can also be more straightforwardly converted into a dependency tree, by establishing a dependency between the anchors of the trees that are the source and target of each derivation edge. For instance, in the previous example, a dependency edge will be established between loves and Tarzan. In the case of non-anchored trees (present in FRMG), a pseudo empty anchor will be positioned in the sentence (on the left-side of the span covered by the tree) and used as source or target of the dependency.
In practice, the FRMG parsers computes all possible parses for a sentences. But rather to return all possible derivation trees, it may return them under the form of a shared derivation forest, generally much much more compact ! The basic idea of shared forests is that subtrees may be shared but also contexts, leading to AND-OR trees.
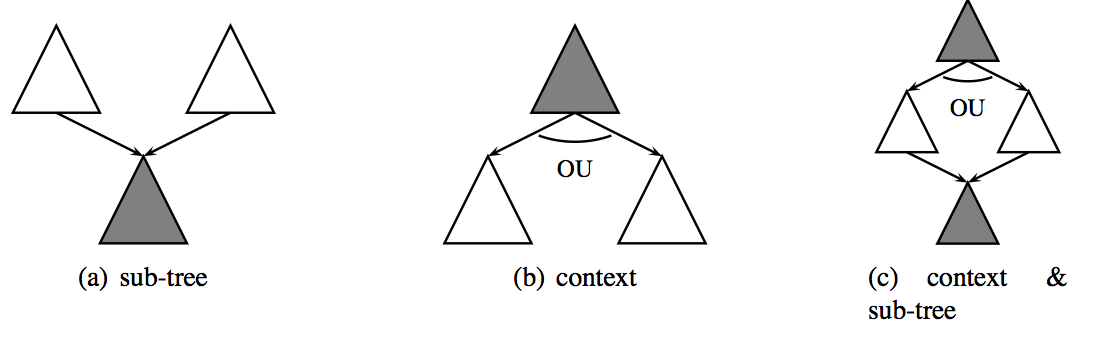
However such AND-OR trees can also be represented under the form of a context-free grammars (an important theoretical result), with terminals and non-terminals decorated with spans over the sentence. Such derivation forests as CFG may be returned by frmg_parser with the option -forest (inherited from DyALog). However, nobody really wants to have a look at them !
A first step is to get a shared dependency forest, following the principles mentioned above (to convert a derivation tree into a dependency tree) but keeping as much as possible sharing. The results is the base for the native DepXML representation of the output of FRMG with the following XML elements (some of them being visible in the graphical view derived from DepXML):
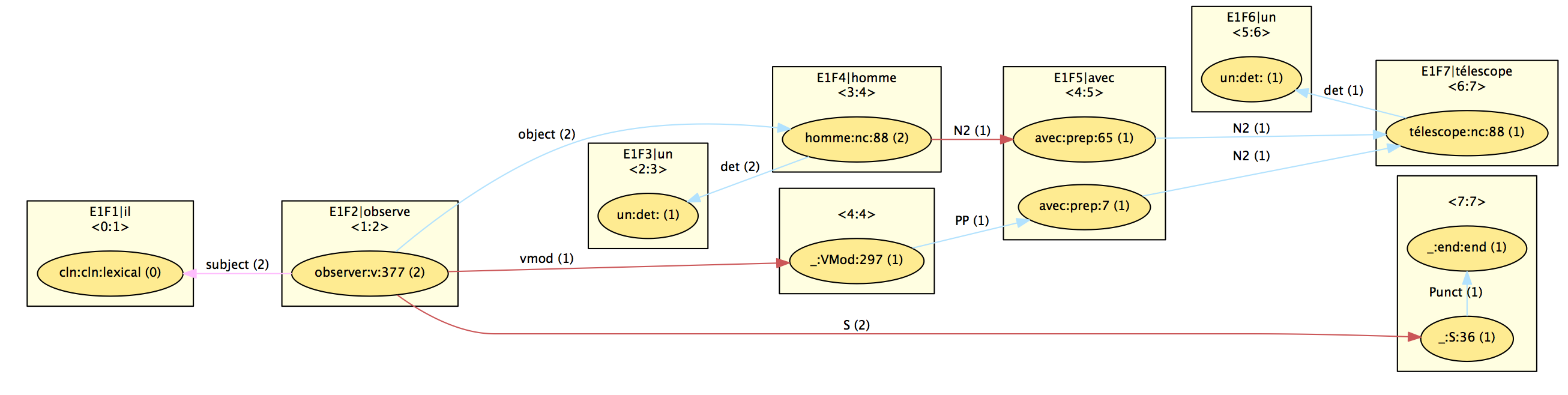
This schema relies on
- clusters, (rectangle) used to list the words of the sentence (possibly with some redundancy because of segmentation/tokenization ambiguities provided by SxPipe)
- nodes, (ellipses) associated to a cluster, a part of speech, a lemma, and generally the tree that is anchored by the node. Because of ambiguities, several nodes may be associated to a same cluster (for instance "avec")
- edges (lines) linking a source node with a target node and with a label and a TAG operation type (substitution, adjoining, ...)
- deriv (not visible) : because of ambiguities, a given edge may actually be used by several of the alternative derivations associated with the source node. For instance, the subject and object edges are used by the 2 possible derivations anchored on "observe", while the vmod edge is used by only one of them.
- op (not visible) : they correspond to the constituent covered by an elementary tree and are characterized by a span, a root syntactic category (such as S, or N2), and a set of derivations
- hypertag (not visible) : they provide the hypertag feature structure used to anchor a tree (op) by an anchor (node). Because of ambiguities, a same hypertag may be associated to several derivations.
Disambiguation with heuristic rules
Disambiguation is primarily achieved thanks to a set of heuristic disambiguation rules assigning weight to edges. These rules essentially consult information related to a single edge, such as its label, type, source and target nodes (part-of-speech, lexical information, morpho-syntactic features, ...). Some rules may also consult information about adjacent edges (incoming ones to the source node or outgoing ones from the target node). A very small number of rules may also consult alternative edges to the one being evaluated.
For instance, the following rule favors the modal verb edges:
Converting to various output schema/formats
Getting deeper representations
- Version imprimable
- Connectez-vous ou inscrivez-vous pour publier un commentaire