a tour of FRMG, a French (Meta)Grammar
This set of pages (book) is being developed as a 2 hours tutorial to be delivered at PARSEME-COST workshop (Dubrovnik, 26-27 September 2016).
It will also serve as an English introduction to FRMG and this wiki. Comments are welcome !
It should cover the following points:
- a brief description of FRMG and a few words about FRMG wiki
- a brief description of Tree Adjoining Grammars (TAGs) : notion of trees, tree operations, pro and cons of large TAGs
- a presentation of meta-grammars as a solution to design large coverage grammatical descriptions
- modularity and elementary constraints to ease grammatical descriptions
- inheritance hierarchy
- elementary constraints
- nodes
- the class itself (desc)
- equality
- precedence
- dominance (father and ancestor)
- node and class features
- equations
- anonymous nodes
- macros and other short notations
- resource producers/consumers
- guards as complex constraints
- browsing the classes
- getting more compact grammars through tree factorization
- disjunction
- guards
- interleaving or free node ordering
- repetition (Kleene star)
- browsing the grammar
- in frmgwiki
- some statistics about the trees
- hypertags to link trees and anchors
- Playing with the resulting parser
- trying a few sentences
- playing with disambiguation
- highlighting edges
- the preprocessing steps
- Tokenizing with SxPipe
- lexicon Lefff and FRMG lexer
- installing the Alpage processing chain
- disambiguation and beyond
- shared forest
- derivations vs dependencies
- hand-crafted disambiguation rules
- injecting some knowledge
- the hard life : how to conciliate coverage, accuracy, and efficiency !
- efficiency
- a few sources of inefficiency (parser & disambiguation)
- using TIGs
- factorization
- lexicalization
- left-corner (lctag)
- restrictions
- guiding (by self training)
- tagging
- hypertagging
- leftcorner restrictions
- a few stats
- coverage
- using test suite and regression
- using error mining
- using robust partial parsing
- using correction rules
- accuracy
- learning from the French TreeBank
- combining with DyALog-SR, a transition-based statistical parser
- domain adaptation with unsupervised learning (self-training)
- feature engineering
- efficiency
- FRMG and MWEs
- at the level of SxPipe (named entities and some frozen expressions such as complex csu)
- at the level of the parser (+ metagrammar) : predicative nouns and light verbs
- at the level of the metagrammar : idiomatic expressions
- at disambiguation level (terms)
- the conversions issues for output schema with different notions and lists of MWEs
- Discussion(s):
- developing and maintaining a large coverage meta-grammar
- starting a meta-grammar for a new language
- re-using meta-grammar components (hierarchy, classes)
- exploring new target formalisms
References:
| Fichier attaché | Taille |
|---|---|
| 439.75 Ko |
FRMG in a few words
From a far away perspective, FRMG is essentially a large coverage hand-crafted grammar for French that may be used to parse sentences and to produce syntactic structures (parses).
Hand-crafting large grammars (or Grammar Engineering) was the way to develop parsers 20 years ago for several important grammatical formalisms such as Tree Adjoining Grammars (TAG), LFGs, HPSGs, CCGs, ...
The arising of successful (supervised) data-driven approaches have since then largely superseded hand-crafted grammars and grammar engineering.
Several weaknesses have been advanced against hand-crafted grammars:
- they require a strong expertise both on the linguistic side and about the grammatical formalism (TAGs, LFGs, ...). The data-driven approaches allow a separation between people with linguistic expertise to annotate treebanks on one side and people skilled in machine-learning on the other side.
- it is difficult to increase the coverage of the grammar, because of the large diversity of rarer and rarer syntactic phenomena to cover but also because of the increasing complexity of the interactions between the different structures of the grammar
- it becomes also more and more difficult to maintain the grammar over time, to modify it and to extend it
- it becomes more and more difficult to extract the right parse from larger and larger search spaces without probabilities (on grammatical structures or operations on the structures), and probabilities requires data !
- efficiency becomes an issue with more and more structures, and more and more interactions between them (larger search spaces). Again, propabilities seems to be the key to prune as soon as possible the search spaces (the extreme case being the greedy parsers such as Malt).
These weaknesses are largely true, but we can also list some advantages of hand-crafted grammars
- even if difficult, they can be understood, when most data-driven approaches produce black-box models or non-linguistic grammars
- it is also possible to extend them to cover new syntactic phenomena, something difficult with data-driven approaches without modifying/extending the training treebank
- they tend to be more robust over various domains and benefit from the tendency of grammar designers to be as generic as possible when describing a phenomena, when data-driven tend to be strongly dependent on their training treebank
- a lesser known fact is paradoxically their capacity to fail on some sentences, hinting (sometimes) to yet uncovered syntactic phenomena when a statistical parser will happily provides a probably erroneous parse !
The development of FRMG over the last 10 years is here to prove that is possible to develop and maintain a large coverage grammar over a relatively long period of time, relying on good choices at the beginning and using many grammar engineering tricks since then.
One of the last of these engineering tricks is the development of FRMG Wiki, as a way to present the grammar, to offer a way for people to try the parser, to provide feedback, and also to discuss complex or missing syntactic phenomena. Sentence parses can also be easily in wiki page, as done for the following sentence "whoever you are, be welcome!"
|
Graph
|
This tutorial will take place in this linguistic wiki, with the objective to show the different components of FRMG.
So, it is now time to look more closely at FRMG, whose acronym stands for FRench MetaGrammar. It is primarily a wide coverage abstract grammatical description for French.
Metagrammars could theoretically be directly used to parse sentences. However, they have been mostly designed to ease the work of syntacticians to describe grammatical phenomena using elementary constraints and a modular organization. In practice, metagrammars are then used to derive an operational grammar, a Tree Adjoining Grammar (TAG) in the case of FRMG. The operational grammar is then compiled into a chart-like parser. At this point, a lot of efforts has still to be deployed to get an efficient, robust, and accurate parser !
Some background about TAGs
TAGs for dummies
Tree Adjoining Grammars (TAGs) have been introduced by Joshi. The basic idea is that complete parse trees can be progressively built by combining elementary trees, using substitution and adjoining.
Elementary trees are formed of initial trees and auxiliary trees.
An initial tree $\alpha$ whose root node $R$ is labeled by syntactic category $X$ may be substituted at a frontier substitution node $N$ of some other tree also labeled by $X$.
An auxiliary tree $\beta$ has an unique frontier foot node $F$ sharing a same syntactic label $X$ with its root node. The path from root to foot node is the spine of $\beta$. The auxiliary tree $\beta$ may adjoin on an internal node $N$ of some other tree also labeled $X$. $N$ is then replaced by $\beta$, the subtree rooted at $N$ being attached below the foot node $F$ of $\beta$.
We have already mentioned foot and substitution nodes as possible kinds of frontier nodes. Other kinds include lexical nodes to be matched by identical lexical content in the sentence during parsing. Trees with lexical nodes are said to be lexicalized. The grammar is said lexicalized if all trees are lexicalized, which is the case for most TAGs but not an obligation.
The following figure illustrates the use of a few simple elementary tree to derive a complete parse tree for sentence "John sleeps a lot". We observe the substitution of node $NP$ in the tree anchored by sleeps by the tree anchored by John. We then observe the adjoining of the complex adverb "a lot" at the level of the $V$ node. In the present case, we see that adjoining is only adding new node on the right side of the adjoining node $V$.
.

From a linguistic point of view, TAGs have two main advantages
- an elementary tree provides an extended domain of locality where a single tree may for instance includes a verb and its expected arguments given its valence. For instance, a tree for verb "to give" will cover substitution nodes for a subject argument, a direct object argument, and an indirect prepositional argument introduced by "to" , in relation with the usage frame "someone gives something to someone". The lexical node like a verb that governs a set of expected arguments is said to be the anchor or head of the tree.
- a better handling of so called long distance dependency through the recursive use of adjoining that can insert an arbitrary amount of nodes between two nodes of some elementary trees
From a parsing point of view, an important property of TAGs comes the possibility to parse a sentence of length $n$ with a worst-case complexity in $O(n^6)$. For real-life grammars, the complexity is less than that, in particular because they are are mostly TIGs, a restricted subkind of TAGs to be described later.
Decorating trees
Tree nodes may be decorated by feature structures to provide additional morphosyntactic, syntactic, or even semantic constraint. It is for instance possible to ensure agreement constraints in number and gender between a subject and its verb. In first approximation, a feature structure is essentially a set of property=value pairs, where property may denote for instance number, gender, tense, mood, animacy, etc and value may be a variable (to establish constraints between several nodes of a tree) or some specific value generally taken in some finite set of values. For instance, the finite set of values for the gender property is masculine|feminine for French, a possible set of moods for verbs would be infinitive|indicative|participial|gerundive|imperative|... . Some examples of such properties and finite set may be found here and are generally part of the tagset (vocabulary) for a grammar.
For TAGs and because of adjoining, the nodes are actually decorated with a pair $(top,bottom)$ of feature structures. When no adjoining takes place on a node $N$, the two structures are unified (ie. made equal by binding the variables to values when necessary). When adjoining a tree $\beta$ on some node $N$, the top structure to $\beta$ root node is unified with the top structure of $N$ while the bottom structure of $\beta$ foot node is unified with the bottom structure of $N$.
Abstracting trees into tree schema
Many trees have the same structure modulo their lexical anchor. For instance, intransitive verbs will have similar trees, similarly for transitive ones. It is therefore usual to consider tree schema where the anchor node is left underspecified until lexicalized at parsing time by the word found in the sentence.
Organizing tree schema into families
Actually, several tree schema may be related the one to the other through transformations associated to syntactic phenomena. The main such transformation corresponds to the extraction of a verbal argument to build wh-sentences, relative sentences, or even topic sentences. In terms of organization and to ease maintenance, it is therefore interesting to group such tree schema into families.
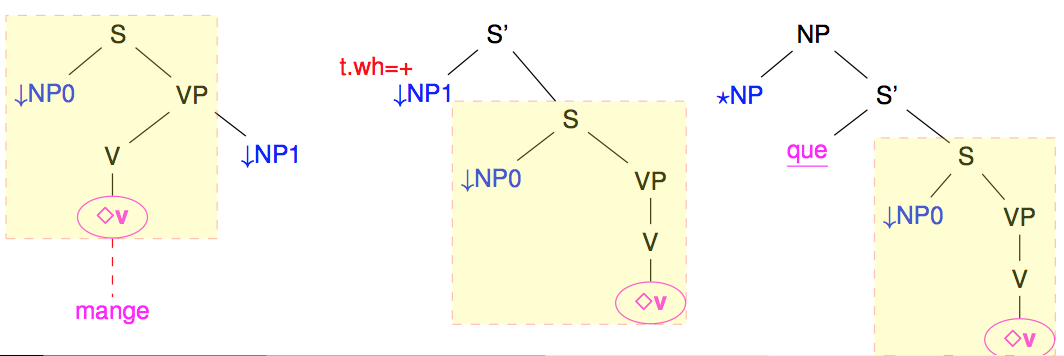
The following figure shows some of the tree schema that belong to the family of the transitive verbs and that be obtained from the left-most "canonical" one to get first a wh version with the extraction of the object $NP_1$ argument and then a relative sentence.
<
p class="align-center">
Families are a nice tentative to organize TAGs. However, as seen in the previous figure, the trees in a same family tend to share large subparts (in yellow). Modifying/correcting one of these trees generally means that all the other trees in the family needs to be also modified. Maintenance becomes relatively complex. Also, because of the number of syntactic transformations, the number of families and trees may grow very quickly. The border between families may also become a bit arbitrary. Should the extraction on the subject argument or the object argument lead to distinct families ? Should intransitive, transitive, di-transitive verbs lead to distinct families, even if they share many subpart of their trees ?
The standard organization model for TAGs (as found in the XTAG grammars developed by Joshi's group at UPenn) leads to very large grammars, with several thousand of trees whose maintenance becomes difficult. Efficiency at parsing time also becomes an issue.
FRMG offers two way to overcome these difficulties:
- sharing descriptive parts through the use of a modular descriptive formalism, namely Meta-Grammars
- sharing subtrees through factorized trees thanks to the use of regexp-like operators
Introducing Meta-Grammars
A modular organization with inheritance
A meta-grammar is organized in a modular way through an hierarchy of classes. A class is a bag of constraints used to specify a syntactic phenomena (or just a facet of it) .
The classes of FRMG may be browsed here. Once a class is selected, the right side panel "Class Graph View" may be used to navigate through the class hierarchy.
The following figure shows a fragment of the FRMG hierarchy (the full hierarchy is too large and deep to fit on a page)

As an example, a very basic class for adverbs will only specify that we expect an elementary tree anchored by an adverb. No more !
We can define subclasses that inherits all the constraints from its parent class and that may be used to progressively refine syntactic phenomena.
For instance, we may have a subclass of adverb specifying constraints about the use of adverbs as modifiers (their most common usage), essentially indicating that we expect an auxiliary tree.
We can then further refine into the notion of adverb as modifier of verbs, by specifying that the root node should have category v, with maybe some other restriction on the type of the adverb.
Combining resources
Besides inheritance, modularity is ensured through the use of another very powerful mechanism, namely by providing/consuming resources. A class may require some resource (or functionality) that will be provided by some other class. For instance, the previous class adverb_as_modifier may be implemented by requiring the functionality of "modifier of something" through asking for resource x_modifier. The class x_modifier will be used to provide this resource. Several classes may be in competition to provide a same resource, and several classes may require a same resource.
This resource management mechanism is quite powerful and nicely complements inheritance. In particular, it has been extended to allow a resource to be consumed several times by a class using distinct name spaces, something that can't be easily done through inheritance.
For instance, a basic resource agreement may be defined to provide agreement on gender, number, ... between a node N and its father node. This resource is consumed twice in class superlative_as_adj_mod, once in namespace det and one in namespace adj, acting on different nodes each times.
However, historically, resources were mostly introduced for verbs to accept several verbal arguments, each one being seem as requiring a arg resource, as implement in class verb_categorization.
Inheritance and resources form the backbone of a meta-grammars (its organization in terms of class). The "flesh" is provided by the content of the classes, through constraints over the nodes of the elementary trees.
Topological constraints
First, we have topological or structural constraints:
- equality between nodes
- precedence: a node should precede another one in a tree
- dominance: a node should dominate another one in a tree. We distinguish the parent dominance (a node is a father of another one) and the ancestor dominance (a node is an ancestor of another one)
For instance, in first approximation, in a sentence, the Subject node should precede its verb node, and both nodes are dominated by the root S node. We can be more precise and state that S should be the father of the Subject.
Decoration constraints
We have also constraints over the decorations carried by the nodes. The decoration constraints may be directly carried on nodes, or expressed as equations between feature paths and values. The source of a feature path is generally a node, but can actually be the class itself denoted by desc (equivalent to this or self in object-oriented languages) or a variable (prefixed by $ as in $foo).
Guards
Going further, the equations may also used to express constraints on the presence or absence of a node. A positive or negative guard on a node is expressed as a Boolean formula over equations.
These guards may be also be used to specify complex constraints over a node without the need to increase the number of classes.
Misc.
To shorten descriptionsm, it is also possible to define and use macros on feature values and feature paths.
When debugging the meta-grammar, it is possible to disable a class and all its descendants
disable verb_categorization_passive
As often (always ?), the formalism provides its set of "hack" that may useful to known. For instance, nodes have a feature type, with a few special type values:
- alternative: for a internal node acting as a disjunction over its children (only one of them may be used at parsing time)
- sequence: for a internal node that has no linguistic interest (no category, no features) but having children
These special types are in particular used to build factorized trees.
It is also possible to state that a node is optional without a guard but by using the optional feature.
It is also possible to state that a node can be repeated zero, one, or several times in the parse trees, in a way similar to the Kleene star operator "*" used in regular expressions.
Tree factorization to get compact grammars
We have seen that a large coverage TAG may have many trees (several thousand trees, and easily more), but with the elementary trees sharing many fragments. For efficiency reason, it is interesting to reduce the number of trees by factorizing them, sharing the common parts and using regexp-like regular operators to handle the other parts. These regular operators, like the disjunction, does not change the expressive power of the TAGs because they can always be removed by unfactorizing to get a finite set of equivalent non-factorized trees.
Disjunctions
When several subtrees may branch under a same node, we may use a disjunction to group the set of alternatives subtrees. For instance, the following figure shows how several possible realizations of French subjects (as Nominal Phrase, clitics, or infinitive sentences) may be grouped under a disjunction node (noted as a diamond node).
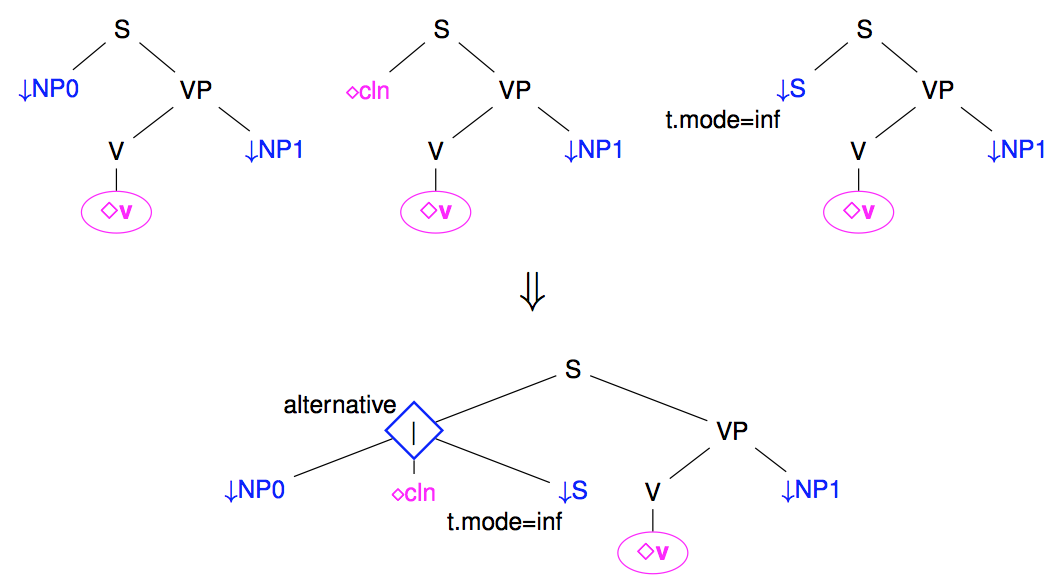
Note: Disjunction nodes are associated with type: alternative in meta-grammar descriptions
Guards
Disjunction may be used to state that a subtree rooted at some node $N$ is present or not. The node is then said to be optional (noted as optional: yes in the metagramar).
However, the presence or absence of a subtree is often controlled by some conditions. Such situations may be captured by guards on nodes, with the conditions being expressing as boolean formula over equations between feature paths (and feature values).
The following figure illustrates the use of a guard over the previous subject disjunction node to state that a subject is present in French when the verb mood is not infinitive, participle, or imperative, and absent otherwise.
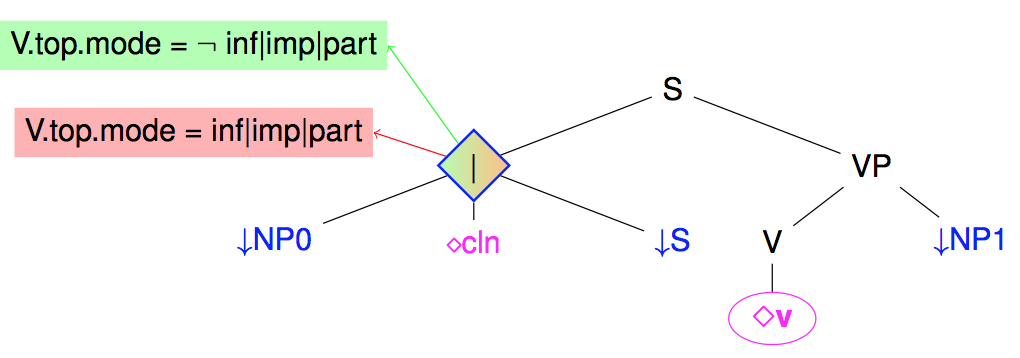
Note: at the level of meta-grammars, the guards are essentially introduced by the => operator on nodes.
For a positive guard on a node $N$ (ie the conditions for its presence) :
For a negative guard on $N$ (ie conditions for its absence), the node must be prefixed by ~
A positive (resp. negative) on a node $N$ implicitly implies a true negative (resp, positive) guard, to be then refined by explicit guards. All occurrences of guards on $N$ are accumulated using an AND operator.
It may also be noted that even if a node $N$ is always present, it may be interesting to set up a positive guard on $N$ to represent different alternatives. A special notation may be used for that case and it implicitly sets a fail condition on the absence of $N$ (i.e. the node $N$ can't be absent!)
Free ordering (shuffling)
Some language are relatively free in terms of ordering of the constituents. This is not really the case for French, but for the placement of post-verbal arguments. Rather than multiplying the number of trees for each possible node ordering, it is possible to use shuffling nodes that allows free ordering between their children.
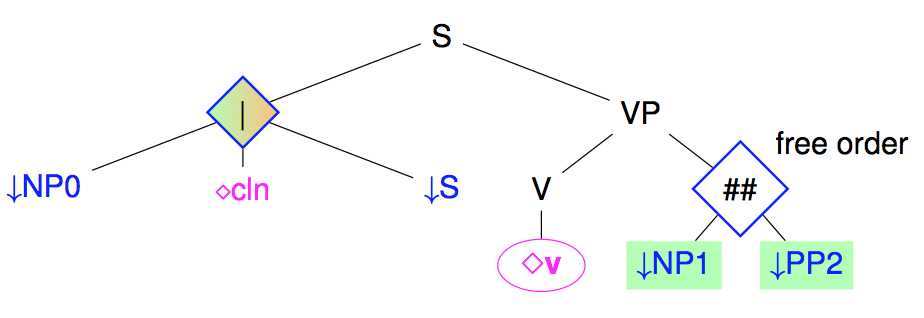
Note: at the level of meta-grammar, there is no need to explicitly introduce shuffle nodes. If the ordering between brother nodes is underspecified given the constraints of the meta-grammar, a shuffle node will be introduced in the generated tree.
Note: The shuffle operator is actually more complex than just presented. It works between sequences of nodes rather than just between nodes, interleaving freely the nodes of different sequences but preserving order in each sequence. For instance, shuffling the two sequences $(A, B)$ with $(N)$ will produce the 3 sequences
- $(A, B, N)$
- $(A, N, B)$
- $(N, A, B)$
If we examine our example tree, we can count how many trees it represents when unfactoring it (assuming guards on subjects and optionality on $NP_1$ and $PP_2$). We actually get $(1_{no\ subj}+3_{subj}) * (1_{no\ args}+2_{1\ arg}+2_{2\ args}) = 20$ trees.
Repetition
The last operator is not used so much in practice and corresponds to the repetition operator $\star$ found in regular expressions. As suggested by its name, it can be used to repeat zero, one or more times some subtree. In FRMG, it is essentially used for representing the iterative part of coordination (, X) between a conjunction of coordination.
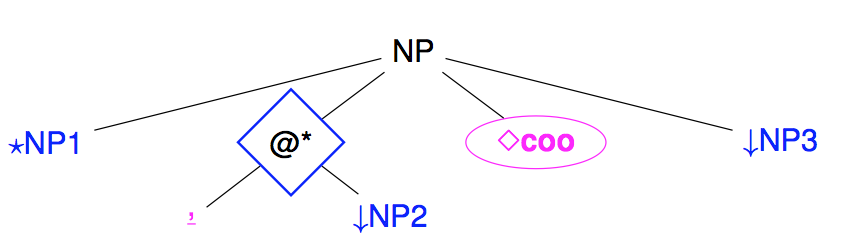
Note: At the level of meta-grammars, repetition is introduced by a node with type: sequence and the special property star: *. This star property is still weakly used but it is planned in some future to specify in a finer way constraints on the number of repetitions (at least one, less than X, more than Y, ...)
Browsing the grammar
The trees of the FRMG grammar that are compiled from the FRMG meta-grammar may be searched and browsed here.
it may also be noted that when using the parsing interface on a sentence, the trees that have been used are listed at the bottom of the right panel.
Producing the grammar from the meta-grammar
We have a meta-grammar description from one part and we know what kind of trees we wish to get at the end, namely factorized ones. It remains to explain how move from a met-grammar description to factorized trees, through the use of mgcomp, the meta-grammar compiler (implemented on top of DyALog).
There are 3 main steps during this compilation:
- Terminal classes in the meta-grammar hierarchy (i.e. those without subclasses) inherit the constraints of all their ancestor classes.
- Iteratively, starting with the terminal classes, a class $C_1[-r \cup K_1]$ expecting some resource $r$ will be crossed with a class $C_2[+r\cup K_2]$ providing the resource $r$ and the resulting class $C[=r \cup K_1 \cup K_2]$ will inherit the constraints of both $C_1$ and $C_2$ except for the the resource $r$ that is neutralized (this scheme is slightly more complex for resource under namespaces).
This step stops with a set of neutral classes, i.e. classes that require or provide no resources.
From this set, we consider the subset of the viable neutral classes, i.e. those whose constraints are all satisfiable.
When checking constraints, we also reduce as much as possible guards, by removing trivially true equations, cutting failed alternatives, ... - For each viable neutral class $C$, we generate a set of minimal (factorized) trees that are compatible with the constraints of $C$. By minimal, we mean that only nodes mentioned in the constraints of $C$ are used to build trees (and all of them should be used). This generation process is actually relatively complex, in particular to get the shuffling nodes resulting from underspecified orderings between sequences of brother nodes.
Practically, the process of getting a grammar from the meta-grammar involves several conversion of formats and the compilation presented above. It is illustrated by the following figure.
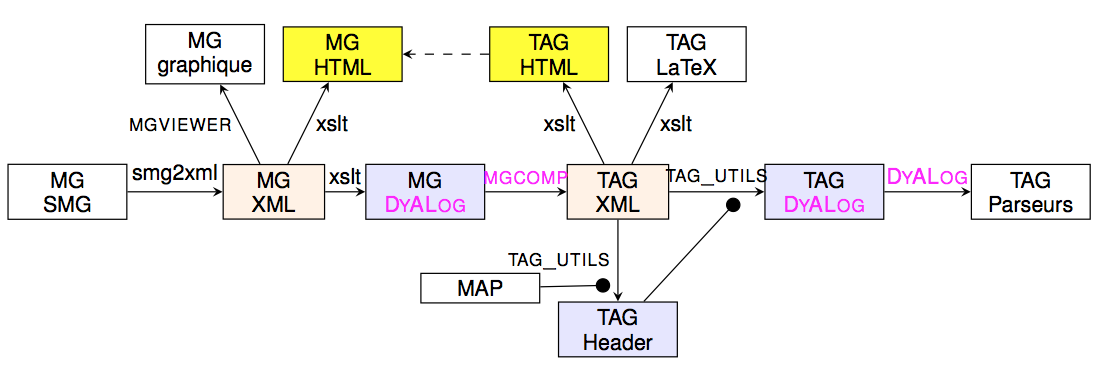
The meta-grammar is written in SMG format, a format more convenient for human writers. It is then converted into XML and then in a Prolog-like format suitable as input for the compiler mgcomp. The resulting grammar is produced in an XML format that may be used to derive several views (including a LaTeX and HTML ones). One of these views is a Prolog-like one that is compiled to get a parser. It is interesting to note that an analysis of the grammar is done to extract a set of features and the sets of values for these features, providing a kind of tagset for the grammar. The process may be eased by directly providing some information through a MAP file. The resulting tagset (seen as an header file) is used during the parser compilation.
Some statistics about the grammar
Some statistics about the meta-grammar and the resulting trees (updated September 2016)
The following table confirms the strong compactness of the grammar, with only 381 elementary trees
| Classes | Trees | Init. Trees | Aux. Trees | Left Aux. | Right Aux. | Wrap Aux. |
|---|---|---|---|---|---|---|
| 415 | 381 | 57 | 324 | 91 | 184 | 49 |
The following table shows that, surprisingly, the number of tree (schema) anchored by verbs is quite low (only 43 trees), when for other existing TAG grammars, they usually form the largest group. At the difference of most other TAG grammars, one may also note the presence of a large number of non-anchored trees (which doesn't mean they have no lexical nodes, or co-anchor nodes). Actually, most of the trees correspond to auxiliary trees anchored by modifying categories such as adverbs or adjectives. And the main reason why there are so few verbal trees is because it is actually possible to get a very high factorization rate for them. On the other hand, modifiers generally correspond to simple trees that can be adjoined on many different sites (before or a after a verb, between an aux verb and a verb, between arguments, on non verbal categories, ....), a diversity that can't (yet) be captured through factorization.
| anchored | v | coo | adv | adj | csu | prep | aux | np | nc | det | pro | not anchored |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 260 | 43 | 50 | 53 | 23 | 10 | 10 | 2 | 3 | 30 | 1 | 7 | 121 |
The following table confirms the high compactness for verbal trees, with in particular very few trees needed to cover the phenomena of extraction of verbal arguments (for wh-sentences, relative sentences, clefted sentences, or topicalized sentences). For standard TAG grammars, this is these extraction phenomena that lead to a combinatorial explosion of the number of verbal trees. On the other hand, we observe a relatively high number of auxiliary trees associated to modifiers at sentence levels (adverbs, temporal adverbs, participials, PPs, ...). This is in particular due to the modularity and inheritance properties of meta-grammars that allow us to easily add new kinds of modifiers (and there seems to exist quite a large diversity, yet to be captured :-)
| canonical | extraction | active | passive | wh-extraction | relative-extraction | cleft-extraction | topic-extraction | sentence-modifiers |
|---|---|---|---|---|---|---|---|---|
| 8 | 19 | 25 | 10 | 3 | 3 | 7 | 6 | at least 60 |
The following table shows the heavy use of the factorization operators, in particular of guards. Free ordering is essentially used between arguments of verbs (but also of a few other categories). Repetition is only used for coordinations and enumerations.
| guards | disjunctions | free order | repetitions |
|---|---|---|---|
| 3713 (pos=1916, neg=1797) | 234 | 23 | 57 |
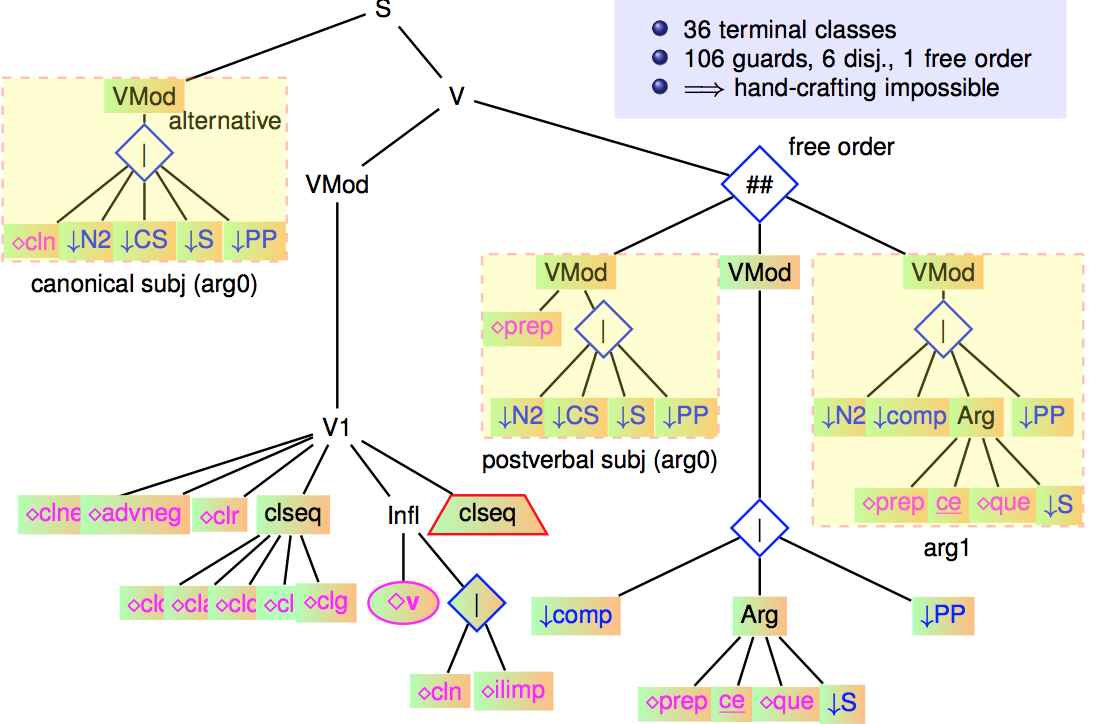
A study of a complex factorized tree
As mentioned, the most factorized trees are those anchored by verbs (verbal trees) and in particular, the canonical verbal tree (active voice, no extraction). It results from the crossing of 36 terminal classes, which themselves inherit from all their ancestor classes.
The following figure shows a slightly simplified version of this tree.
<
p class="align-center">
Experiments were tried (in 2007) to unfactorize this tree. It led to more that 2 million trees ! Trying partial unfactoring by keeping disjunctions and by filtering out verb categorization frames not found in Lefff lexicon, we get only (!) 5279 trees ! It was possible to parse with the resulting grammar, but it was not possible to exploit all optimizations on it (in particular using a left-corner relation). The grammar was tried on a set of 4k sentences (EasyDev corpus), with the following results:
| parser | #trees | avg time (s) | median | 90% | 99% |
|---|---|---|---|---|---|
| +fact -left-corner | 207 | 1.33 | 0.46 | 2.63 |
12.24 |
| -fact -left-corner | 5935 | 1.43 | 0.44 | 2.89 | 14.94 |
| +fact +left-corner | 207 | 0.64 | 0.16 | 1.14 | 6.22 |
We show that without the left-corner optimization, both version of the grammar (with or without factorization) exhibited similar parsing times (a bit slower for the unfactorized version). However, the left-corner optimization is essential to get much more efficient parsers but is too heavy to be computed over very large grammars.
Hypertags
In FRMG, there is no clear notion of tree family and in particular no family of intransitive verbs, transitive verbs or ditransitive verbs. A verbal tree like the one presented above may be anchored by all kinds of verbs, be them intransitive, transitive, ditransitive, with PP args, or with sentential args, ...
So one may wonder how a verb may control the arguments that should be allowed in the verbal tree ?
Actually, each anchored tree $\tau$ has an hypertag $H_\tau$ (coming from desc.ht), which is a feature structure providing information in particular about the arguments that are covered by $\tau$. Similarly, a verb $v$ will carry an hypertag $H_v$ build from it lexical information that specifies which kinds of arguments are allowed for $v$ for which realizations. When $v$ is used to anchor $\tau$, its hypertag $H_v$ is unified with $H_\tau$, and the variables present in $H_\tau$ will be propagated into $\tau$, in particular in guards.
The following figure shows the unification of the hypertag for the above mentioned trees and the hypertag for verb to promise.
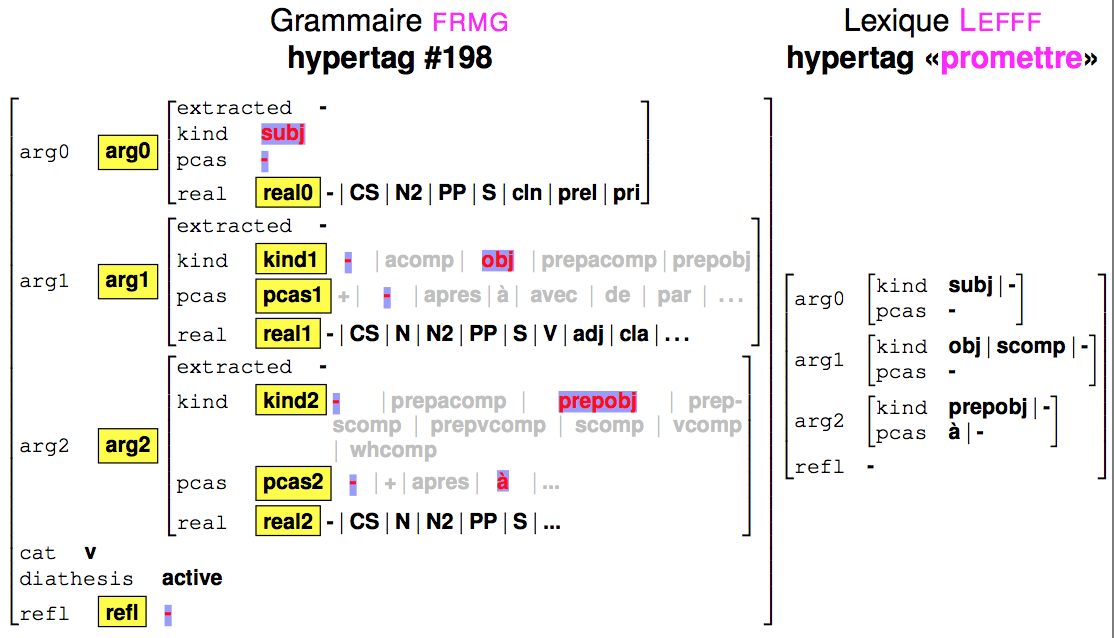
For the anchors, the hypertag information is retrieved from the lexical entries of Lefff lexicon:
Playing with the parser
Recipes for the impatients
The parsing interface
The best way to play with FRMG is to use the parsing interface available on this wiki, also accessible in the left side panel. The Schema menu allows you to select an ouput schema. The other options activate extra functionalities, such as returning partial parses when no complete parse can be found for a sentence (robust mode). Some of these functionalities are still experimental, like the advanced mode for dealing with ellipses in coordinations, renaming some edges, or removing some edges and nodes (essentially the nodes corresponding to non-lexicalized trees represented by empty pseudo-anchors).
More information about using the interface may be found here. In particular, it is possible to switch to full-screen or to fold a tree to focus on the interesting parts. A parse can also be edited, either by exploring parse alternatives (just click on a target node to see all potential incoming dependency edges) or even by adding or deleting edges. Finally, the edges may be highlighted, an interesting functionality to point to errors (in a discussion) or to pinpoint the key characteristics of a syntactic phenomena (its signature).
Actually, the signatures are used to propose a list of related pages (top right side panel) where are discussed syntactic phenomena. This mapping is still very experimental and far from being perfect !
A sentence parse may also be saved and added to a basket. It may also be proposed as a sentence of the day (the final decision being mine !). And as seen, sentence parses can easily be inserted in wiki pages to illustrate syntactic phenomena (especially when highlighting its signature) or to pinpoints weaknesses in FRMG analysis. Finally, the parses come with leftmost up and down hands that may be used to provide your opinion about their correctness.
Finally, please note that the parses returned through the interface are not always the best ones one may get with FRMG. Indeed, for efficiency reason and because the parser is started from scratch for each sentence, the use of statistical models for the disambiguation is not activated (the latency time of a few seconds for loading them being too high). However, the corpus processing service uses such models.
The parsing service
The parsing interface actually calls a cruder but more complete parsing service available here. Its interface is less sophisticated but actually accepts a larger set of options and provides a greater variety of output views.
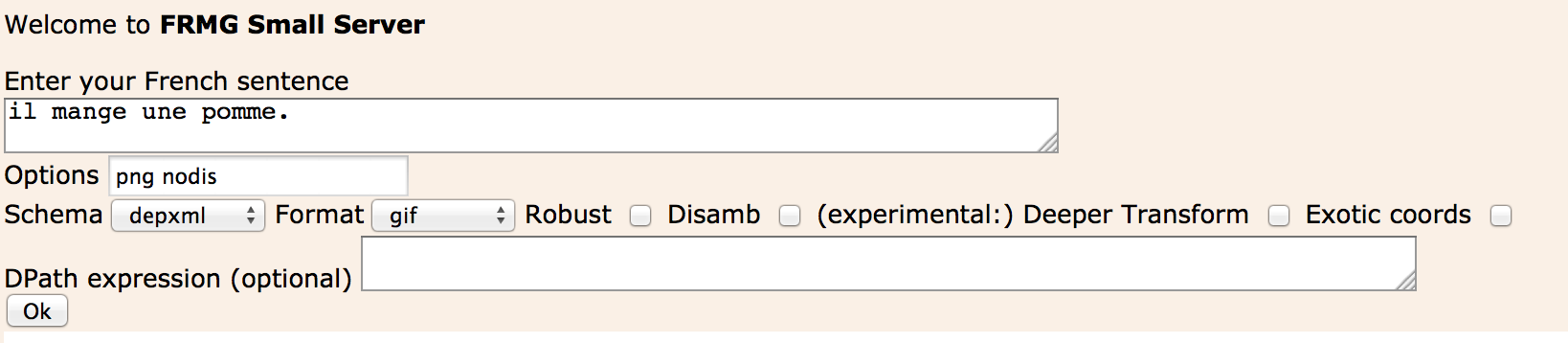
The options should be provided in the Option textfield (the checkboxes are actually not active !)
- png: to get a png image (please note that for an image as output, this option is mandatory)
- nodis: to get the full dependency forest
- xml: to get the xml file with all information
- token: to show the output of the tokenizer (SxPipe)
- lexer: to show the output of the lexer (after consultation of the Lefff lexicon)
- follow: to get an idea of the number of computation tried during parsing at each word of the sentence
- robust: to get partial parses in case of failure to get a complet one for a sentence
- conll, depconll, udep, passage: several output annotation schema
- and many others !
The corpus processing service
FRMG Wiki also provides a service to process small corpora (less than one million words). Il allows to upload a corpus and get the parse results (as an archive) when parsed. It also possible to consult the results online and to query them using the DPath query language, inspired by XPath (with its navigation axes).
Recipes for the geeks
For the courageous geeks, it is possible to install the full processing chain developed by the ALPAGE team, including FRMG (but also SxPipe, Lefff, Aleda, mgcomp, DyALog, Syntax, mgtools, tag_utils, forest_utils, ... ![]() ).
).
All needed packages are freely available under open-source licenses. They may be fetched from INRIA GForge and compiled under Linux and Mac OS environments. The process is however largely automated with the help of the alpi installer, a Perl script that does the job of fetching and compiling the Alpage packages and the missing dependent packages (mostly Perl ones, but also libxml or sqlite).
The alpi script may be found here (Note:it is strongly advised to use the version that is available under SVN, the released one being outdated !). Please note that the compilation of some components (in particular FRMG) requires a relatively powerful computer, with RAM (2 to 4 Go) and disk (at least 10Go). Fortunately, the run time requirements for using the chain are more reasonable !
To install the chain with alpi, fetching the sources from the SVN repositories:
perl ./alpi --svn=anonymous --prefix=<where to install>
For more info, use
perldoc ./alpi
or
perl ./alpi --help
In case of problem, please contact me by mail, attaching the file 'alpi.log' produced by alpi, and providing information about your system, environment, ...
To have more information about using the chain once installed, please have a look here (in French). In particular, a small shell is available, proposing options similar to those of the parser service but completed with an history mechanism.
From (shared) forests to dependency trees and beyond
Shared forests, derivations and dependencies ?
In our first examples with TAGs, we have seen that trees may be combined through substitution and adjoining to get complete parse trees.
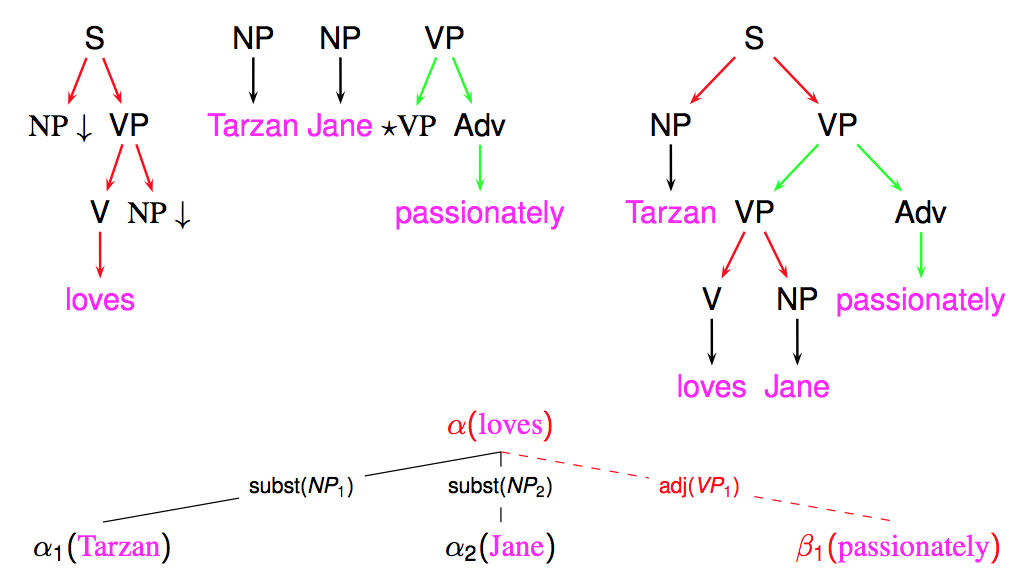
These parse trees may be useful, but what is actually more useful are derivation trees (my opinion, but it may be discussed) ! A derivation tree keeps trace of all operations (substitution or adjoining) needed to build the parse tree, with the indication of the nodes where the operations took place, and of the elementary trees that were used.
The following figure shows an example of a derivation tree
<
p class="align-center">
The interest of derivation tree partly stems from the observation that they better reflect the underlying semantic structure (than parse trees), in particular by relating a predicate (such as a verb) with its arguments (through substitution edges).
A derivation tree can also be more straightforwardly converted into a dependency tree, by establishing a dependency between the anchors of the trees that are the source and target of each derivation edge. For instance, in the previous example, a dependency edge will be established between loves and Tarzan. In the case of non-anchored trees (present in FRMG), a pseudo empty anchor will be positioned in the sentence (on the left-side of the span covered by the tree) and used as source or target of the dependency.
In practice, the FRMG parsers computes all possible parses for a sentence. But rather to enumerate all possible derivation trees, it may return them under the form of a much much more compact shared derivation forest ! The basic idea of shared forests is that not only subtrees may be shared but also contexts, leading to AND-OR graphs.
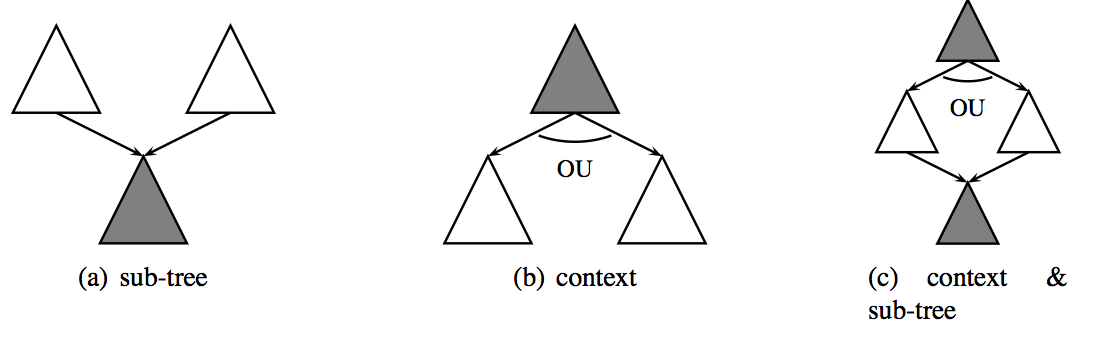
However such AND-OR graphs can also be represented under the form of context-free grammars (an important theoretical result), with terminals and non-terminals decorated with spans over the sentence. Such derivation forests as CFGs may be returned by frmg_parser with the option -forest (inherited from DyALog). However, nobody (but I) really wants to have a look at them !
A first step is to get a shared dependency forest, following the principles mentioned above (to convert a derivation tree into a dependency tree) but keeping as much as possible sharing. The results is the base for the native DepXML representation of the output of FRMG with the following XML elements (some of them being visible in the graphical view derived from DepXML as illustrated below on the famous "he observes a man with a telescope" with prepositional attachment ambiguities):
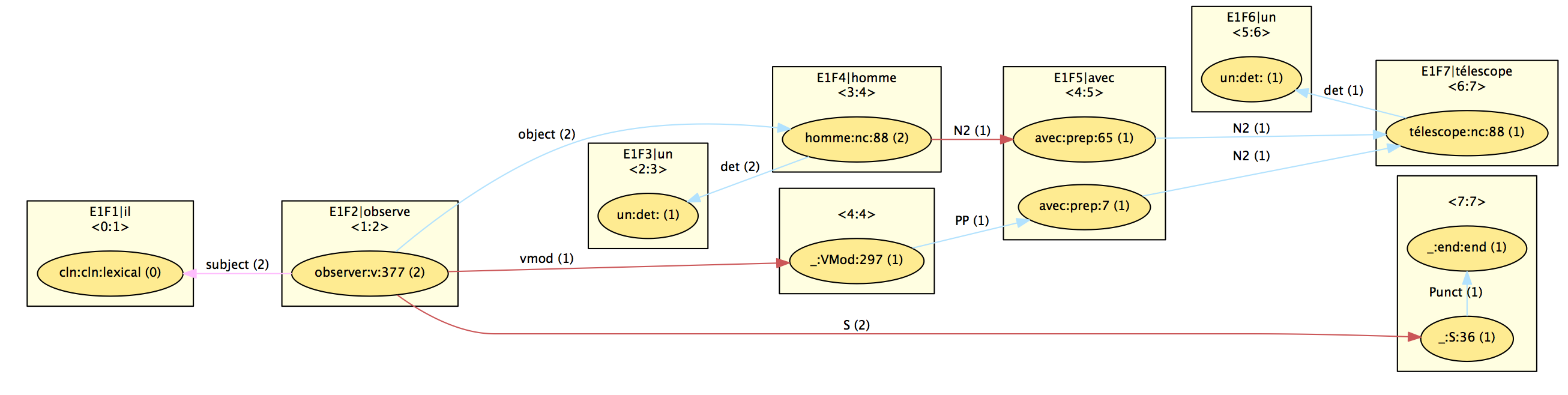
The DepXML annotation schema relies on
- clusters, (rectangle) used to list the words of the sentence (possibly with some redundancy because of segmentation/tokenization ambiguities provided by SxPipe)
- nodes, (ellipses) associated to a cluster, a part of speech, a lemma, and generally the tree that is anchored by the node. Because of ambiguities, several nodes may be associated to a same cluster (for instance "avec")
- edges (lines) linking a source node with a target node and with a label and a TAG operation type (substitution, adjoining, ...)
- deriv (not visible) : because of ambiguities, a given edge may actually be used by several of the alternative derivations associated with the source node. For instance, the subject and object edges are used by the 2 possible derivations anchored on "observe", while the vmod edge is used by only one of them.
- op (not visible) : they correspond to the constituent covered by an elementary tree and are characterized by a span, a root syntactic category (such as S, or N2), and a set of derivations
- hypertag (not visible) : they provide the hypertag feature structure used to anchor a tree (op) by an anchor (node). Because of ambiguities, a same hypertag may be associated to several derivations.
Disambiguation with heuristic rules
Disambiguation is primarily achieved thanks to a set of around 230 heuristic disambiguation rules assigning weight to edges. These rules essentially consult information related to a single edge, such as its label, type, source and target nodes (part-of-speech, lexical information, morpho-syntactic features, ...). Some rules may also consult information about adjacent edges (incoming ones to the source node or outgoing ones from the target node). A very small number of rules may also consult alternative edges to the one being evaluated.
For instance, the following rule favors the modal verb edges:
There also exist a very few number of 14 "regional cost rules" that work for a node $N$ and a set of edges leaving $N$ that form a derivation. One of these rules is used for coordinations to favor coordinations between similar coordinated parts. However, because the number of derivations may be very high (due to ambiguities), the number of regional cost rules is kept very small and they are only used on a subset of the most promising derivations.
Disambiguation computes all edge costs, some regional costs, and return the best dependency tree, using a dynamic programming algorithm.
In its initial (and default) setting, the weights associated to the rules were manually set and already provided a good accuracy (over 80% LAS accuracy on the French Tree Banks). Since then, machine learning techniques have been designed to learn these weights from the French TreeBank, boosting the accuracy around 87%. More details here !
Converting to various output schema/formats
As already mentioned, the native output schema for FRMG is the DepXML one, that may be used both for representing a whole shared dependency forest or a single dependency tree (which partly explains some of the complexity of this schema). It also tries to provide all pertinent information (such as hypertags and morpho-syntactic feature structures).
However, over the years, it became necessary to implement converters to other annotation schema:
- The first of them was the Passage schema that was needed to perform evaluations of FRMG during the EASy and Passage parsing evaluation campaigns for French.
- The second one was the FTB/Conll schema used to represent the dependency version of the French TreeBank (whose original version is annotated by constituent). This second schema allowed us to evaluate FRMG against the dependency version of the FTB and also led to the improvement of the disambiguation process of FRMG. Several variants of this schema have been implemented to cover the variants used for the SEQUOIA Treebank (spmrl variant) and the French Question Bank (fqb).
- More recently, a third converter was added for the French Universal Dependency annotation scheme, to conduct evaluations on the on-going project of UD French TreeBank.
At this point, it is worth mentioning that we have here a clear distinction between symbolic grammars and data-driven approaches. A symbolic grammar is supposed to deliver the parses in relation with its structures and underlying grammatical formalisms. Conversions are needed when dealing with another schema. On the other hand, data-driven approaches learns the schema from the data, and may learn another parser for another schema from another treebank. There is generally no need for conversion.
Conversion between syntactic schema may seem as relatively simple problem. This is not the case !
Even between dependency-based schema, the source and target schema generally differ on their set of dependency labels (easy), part-of-speech (more or less easy), handling of MWEs (difficult), and notion of heads (even more difficult). The difference on the notion of heads means that local modifications of the input dependency structure may not sufficient and that modifications may propagate far away in a sentence.
For instance, in FRMG, modal verbs are adjoined on the main verb, while they are considered as main verbs for FTB and UD, as shown on the following exemples.
|
DepXML view
|
|
FTB/Conll view
|
Another example is provided by the clefted constructions that are seen as a kind of relative construction for FTB/Conll
|
DepXML view
|
|
FTB/Conll view
|
The converters for FRMG are essentially a set of transformation rules. However, to avoid a multiplication of the number of such rules, a notion of propagation has progressively emerged leading to 2-phase rewriting system. The first phase consists into applying basic transformation rules, some of them creating edges with "propagation" constraints. For instance, an edge with an up-constraint will reroot the edges leaving from its target node at the level of its source node.
Getting deeper representations
Thanks to adjoining and the extended domain of locality of TAGs, FRMG is able to provide relatively deep analysis, in particular through long distance dependencies.
However, in the perspective of information extraction application where one needs to know all the actants involved in an event, it is immediate to realize that some of these actants are hidden and not immediately available. Recently, we realized that some information could be added at the level of the meta-grammar to more easily retrieve and materialize these "deeper" dependencies as secondary edges.
The following sentence shows several instances of such deeper dependencies (in gray) for controlling verbs and coordinations, with "lui" being the hidden subject of both "partir" and "revenir".
|
Deep dependencies
|
These deeper dependencies are still experimental. As explored for the converter, they require some notion of propagation to be applied during the conversion of the shared derivation forest into a shared dependency forest, propagation that it not yet complete and correct ! Also, the cost of applying the propagation in a forest is still relatively high.
But nevertheless, it is interesting to observe the effect of propagation on the following complex and somewhat artificial sentence:
|
Graph
|
Another experimental mechanism has been also deployed at the level of the parser to deal with some specific cases of ellipses of coordinations. In these cases, a deeper representation would like to materialize the shared elements and the ellipsed ones. In the parsing interface, this mechanism may be activated by checking the option box "Coordinations (expérimental)"
Checking the option, we get the following parse, where we observe that the ellipses of both "veut" and "donner" are retrieved with their own set of arguments.
|
Ellipses verbe+modal dans Paul veut donner une pomme à Jean et son ami une poire à François.
|
More examples may be found here.
Dompting the beast
The development of FRMG was initiated in 2004 in order to participate to EASy, the first parsing evaluation campaign for French. Developing a first working version for the campaign took less than 6 months, illustrating the interest of meta-grammars to quickly design relatively large coverage grammars.
However, the last 10 years have been busy improving FRMG and have led to the development of several auxiliary tools to monitor, debug, evaluate, ..., in other word, the necessary duties of real-life grammar engineering.
Actually, improving a grammar like FRMG means to work along the 3 following axes:
- improving the coverage, with the description of more and more syntactic phenomena and ways to deal with errors in sentences (robustness)
- improving the accuracy of the parses
- improving the efficiency, ie the speed of parsing but also of the other phases (forest extraction, disambiguation, conversions)
Unfortunately, these 3 axes are not easily conciliable !
Increasing the coverage tends to degrade the efficiency and may also lead to a degradation of accuracy: a new badly constrained rare syntactic phenomenon may overtake some more common phenomena. Improving efficiency may require to prune search space and loose good parses. Improving accuracy may require more disambiguation rules, more discriminative features, leading to longer disambiguation times.
Coverage
The normal way to improve coverage is of course to add new classes in the meta-grammar to cover missing syntactic phenomena. This process may be helped by parsing large corpora and looking at "failed sentences", ie sentences that couldn't be parsed. When modifying the grammar, it is also very important to try test suites and to re-parse corpora to check that sentences that were successful remain successful (for FRMG, FTB train has became such a test with more than 9K sentences).
Actually, there may be many reasons for a sentence to fail, not necessarily because of missing syntactic phenomena. It may also comes from missing or bad lexical entries, new words, badly recognized named entities, exotic typography, spelling errors, ....
In order to better identify the source of errors, we developed error mining techniques, applied when processing new corpora (for new domains such as medical, legal, literacy, subtitles, ...). The algorithm is essentially a variant of EM (expectation maximization) that tries to find suspect words that tend to occur more often than expected in failed sentences and in presence of words that on contrary tend to occur in successful sentences. Error mining proved to be very useful to detect lexical issues, but also to detect exotic typographic conventions and even syntactic issues. Actually, the idea of error mining may be extended to go beyond words, by working at the level of part-of-speech, n-grams, ...
A nice case was provided when parsing the French Question TreeBank, with a set of similar sentences that failed, leading to the addition of just a single class special_cleft_extraction_wh completing special cases of cleft constructions:
|
Graph
|
However, I tend to stay parsimonious when extending the meta-grammar, waiting for a clear generic view of a new syntactic phenomenon (rather than adding a set of related special cases) and trying to have a good understanding of the interactions with other phenomena.
Another way to improve coverage in the robust mode provided by FRMG that may be used to return a set of partial parses covering a sentence that has no full parse. While interesting, the resulting partial parses tend to have a lower accuracy than the full ones, and the robust mode remains a default mode when everything else fails !
More recently, a correction mode has been implemented to be tried before the robust mode. The motivation is the observation that many failures actually arise from "errors" in the sentences, such as missing coma, participles used in place of infinitives (and conversely), agreement mismatch between a subject and its verb (or between a noun and adjective), .... So a set of rules has been added and the correction mechanism detects from left to right if some of these rules apply, proposes a correction (for instance, underspecifying the mood of a verb), and re-parse (but keeping trace of what has been already computed thanks to chart parsing). The correction mechanism is a way to get full parses even in presence of errors. As a side effect, the mechanism also provides a nice way to potentially deliver feedback to an user about his/her errors (first step towards a grammar checker, cf Parslow's master thesis)
|
Several corrections applied on this sentence
|
Accuracy
The basic way is to Improve the set of disambiguation rules and their weights, but it is a really difficult task. Adding or changing a weight may have threadhold effects
Tuning the weights of the disambiguation rules on the French TreeBank have greatly improved the accuracy of FRMG (5-6 points). The algorithm is a kind of batch perceptron, except that it works with lower supervision than usual perceptron. The issue comes from the conversion from DepXML to FTB/Conll:
- when a FTB dependency $d$ provided by FRMG with target $i$ is correct, one may assume that the DepXML dependency $D$ targeting $i$ is also correct and that the disamb rules favoring $D$ should be favored
- when a FTB dependency $d$ provided by FRMG with target $i$ is not correct, one may assume that the DepXML dependency $D$ targeting $i$ is also not correct and that the disamb rules favoring $D$ should be penalized
- however, in that case, we don't know for sure which alternative $D'$ to $D$ should have been kept and which disamb rules should have been favored !
we distribute gains over the alternatives, putting more on good prospects ! - but it should be noted that because of conversion, it is not even clear that $d$ is converted from $D$ !
We also inject knowledge learned from parsing large corpora, using Harris distributional hypothesis (more info here) . We also exploit clustering information (Brown clusters) and, to be tried, word embeddings (also extracted from the parses on large corpora, available here).
Accuracy is controlled very regularly by running evaluations on treebanks, for instance on the EASYDev corpus (Passage schema) and nowadays the French TreeBank (FTB/Conll schema), but also Sequoia TreeBanks and more recently of French Question Bank (FQB) and UD_French treebank (but pb with its quality !)
Several tools have been developed to get finer-grained evaluations and to monitor the differences between successive runs (to check the impact of modification in the meta-grammar and also in other components).
For instance, we have access to
- confusion matrices
- differential confusion matrices
- views of the annotation errors (wrt gold ones)
Efficiency (speed)
Many many ideas have been explored, most of them leading to failures !
We list here some of most successful ones (it would be really difficult to describe all of them into details !)
The first one is obviously tree factorization, but we already talked about it !
Moving to an hybrid TIG/TAG grammar
The worst-case complexity of TAGs is $O(n^6)$ where $n$ denotes the sentence length, when the worst-case complexity of CFG is only $O(n^3)$. The extra complexity actually arises from adjoining, and more precisely from wrapping adjoining where material is inserted on both sides of a spine. There exists a variant of TAGs called Tree Insertion Grammars (TIGs) where no wrapping adjoining takes place, only left and right adjoining. The worst case complexity of TIGs is $O(n^3)$ like CFGs.
And actually, a grammar like FRMG is almost a TIG one. Still, there exists some wrapping auxiliary trees that may "contaminate" left and right auxiliary trees (and I regularly find new rarer phenomena leading to wrapping trees).
Nevertheless, when compiling FRMG, it is possible to determine which auxiliary trees act in a TIG way, and which ones are wrapping one or do not act in a TIG way (even if they have a leftmost or rightmost spine).
| left aux. trees | right aux. trees | wrapping aux. trees |
|---|---|---|
| 91 | 184 | 49 |
Some wapping aux. trees: 'adv_coord coord_ante_ni', comparative_intro_N2 (the same X than Y), incises, quotes,
Using a left-corner relation
When compiling FRMG, a left-corner relation is computed that indicate which syntactic categories and which trees can start given the current word and the next one, using their form, lemma, and part-of-speech.
:-lctag('82 N2_as_comp N2:agreement adjP:agreement',scan,U1__6::lex[assez, 'aussi bien', autant, davantage, moins, plus, 'plut<F4>t', suffisamment, tant, tellement, trop, '<E0> ce point'],['111 comparative_as_N2_mod comparer comparer_ante_position deep_auxiliary']).
The left-corner relation is very efficient at parsing time (times divided by 2 or 3). However, the size of this relation grows quickly with the complexity of the grammar (8K rules for FRMG) and its computation (at compile time) may take some time (and memory). It seems difficult to compute more refined version of this relation (with longer look-ahead).
Using lexicalization to filter the grammar
The word of the sentence are used to filter the lexicalized trees that are potentially usable. The non-lexicalized trees are activated by default. Lexicalization drastically reduces the search space by avoiding to try trees that have no chance to be anchored.
When a tree has several lexical components (anchor + coanchor and/or lexical nodes), the filtering tries to be clever by checking the existence of some (discontinuous) sequence covering the lexical elements.
Using restriction constraints
A mechanism of constraints has been added to restrict some criteria such as the length of a constituent, or the number of dependents for a given tree.
Restricting the search space with endogenous guiding information
Very recently, because of a strong degradation of the parsing times, I started investigating the use of guiding information such as tagging information to reduce the search space.
Tagging is a standard processing step that is not used by default in FRMG. Instead FRMG processes all lexical and tokenization ambiguities returned by SxPipe and FRMG Lexer.
For the tagging experiments, we have combined MELt with a model trained on the FTB, but also another model trained on the output of FRMG (without tagging). Tags were assigned to words only when both models agreed and have a high level of confidence for the label (over 98%). Ambiguities were kept for the other words.
Another step was to attach supertags on words. These supertags are actually tree names and are attached on their potential anchors. MElt was tried to learn a model from the outputs of FRMG on the FTB but the model was not good enough. Another model was then trained using DyALog-SR as a fast dependency parser, seeing the supertags as dependency labels between an anchor and its governor.
A last step dubbed lcpred was to learn the probabilities to start a tree at some position given local information (the current word and the next word). Only the n-best trees are kept, hence restricting the left-corner relation. Again the learning was done on the output of FRMG on FTB. lcpred may be seen as a way to restrict the possibilities of the left-corner relation (it could also be a way to attach probabilities on it).
So, a key characteristic of these guides is that the learning is done on the output of FRMG (without guides). The primary aim is not to improve the accuracy of FRMG but rather to restrict to the most probable choices FRMG would have made without guiding, pruning the other ones. However, I've also observed gains in accuracy.
Of course, the guiding is not perfect and tend to degrade coverage. So, mechanisms were implemented to try the discarded alternatives in case of parse failure (they take place after normal parsing and before trying corrections, and then partial parses)
Reducing ambiguities
The best way to improve efficiency remains to better constraint the syntactic phenomena in the meta-grammar, without loosing too much in terms of coverage. A rough way to monitor that at parsing time is to check the level of ambiguity in parses using several ambiguity metrics, one of them being the avg number of governors per word.
Another way to show ambiguity points is to follow how search space is explored when advancing in a sentence. It can be done using the follow option is the parsing service.
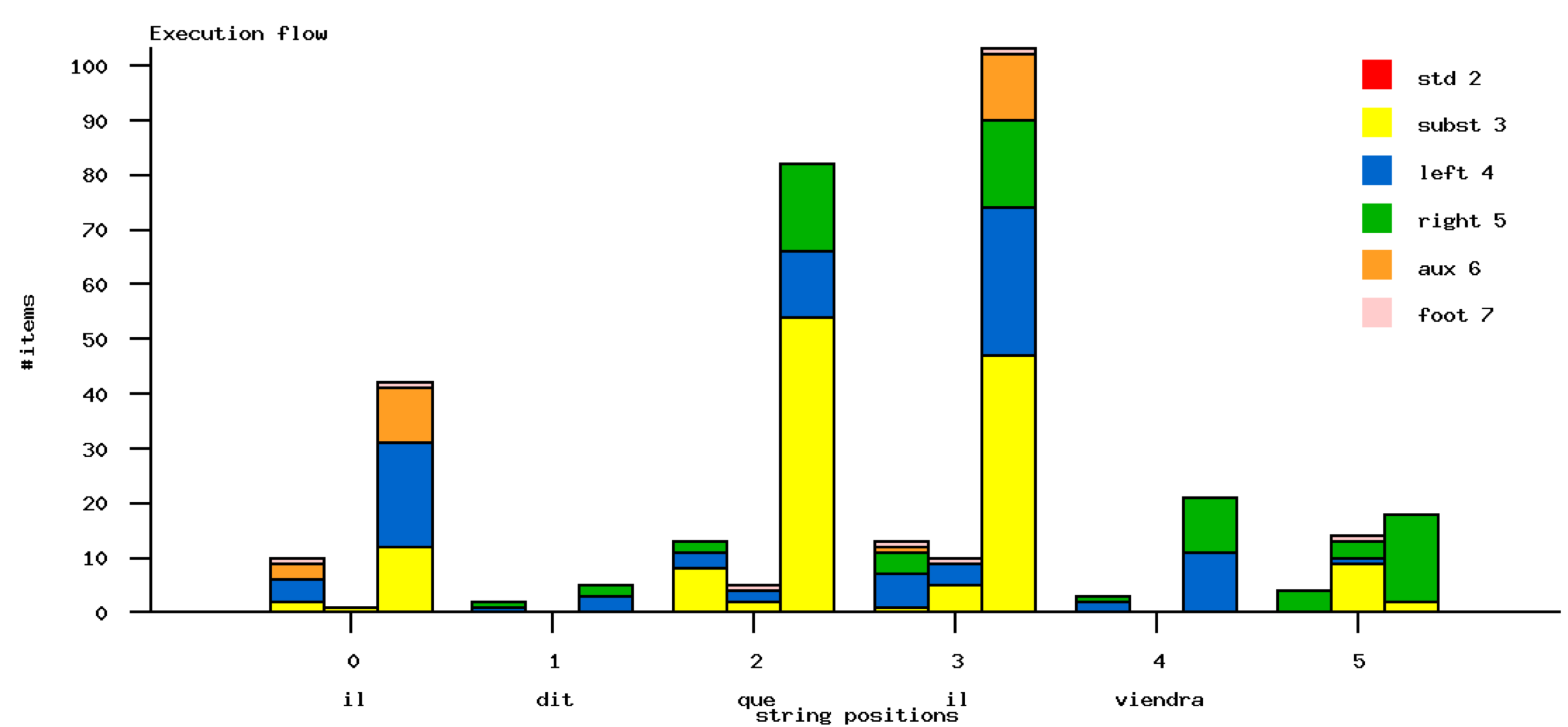
Looking at performances
We provide several elements of information about the past and current performances of FRMG.
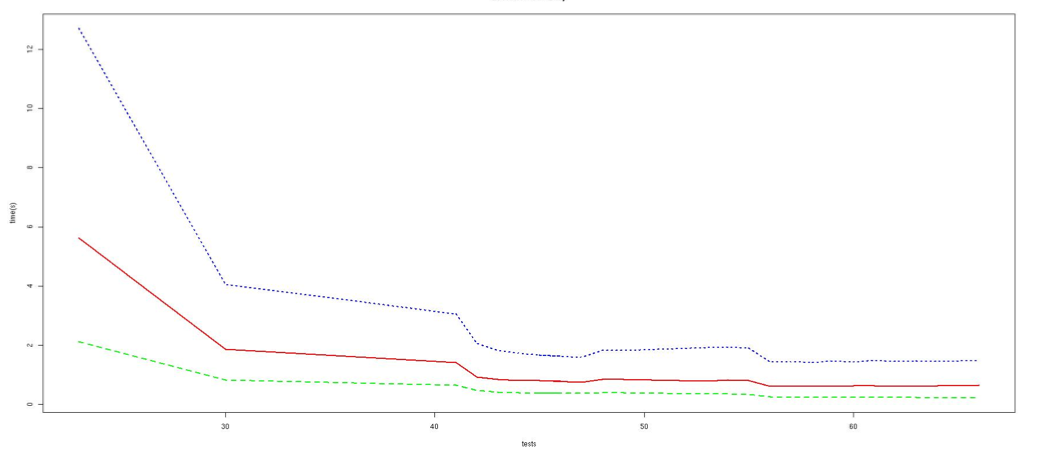
| Corpus | #sentences | %coverage | avg time (s) | median time (s) |
|---|---|---|---|---|
| FTB train | 9881 | 95.9 | 1.04 | 0.26 |
| FTB dev | 1235 | 96.1 | 0.88 | 0.30 |
| FTB test | 1235 | 94.9 | 0.85 | 0.30 |
| Sequoia | 3204 | 95.1 | 1.53 | 0.17 |
| EasyDev | 3879 | 87.2 | 0.87 | 0.14 |
| French TreeBank (LAS, no punct) | Other Corpora | |||||
|---|---|---|---|---|---|---|
| Parsers | Train | Dev | Test | Sequoia (LAS) | EasyDev (Passage) | |
| FRMG | base | 79.95 | 80.85 | 82.08 | 81.13 | 65.92 |
| +restr | 80.67 | 81.72 | 83.01 | 81.72 | 66.33 | |
| +tuning | 86.60 | 85.98 | 87.17 | 84.56 | 69.23 | |
| 2014/01 | 86.20 | 87.49 | 85.21 | |||
| 2015/03 | 86.76 | 87.95 | 86.41 | 70.81 | ||
| Other Systems | Berkeley | 86.50 | 86.80 | |||
| MALT | 86.90 | 87.30 | ||||
| MST Parser | 87.50 | 88.20 | ||||
| dyalogs-sr | raw | 88.17 | 89.01 | 85.02 | ||
| guided by FRMG | 89.02 | 90.25 | 87.14 | |||
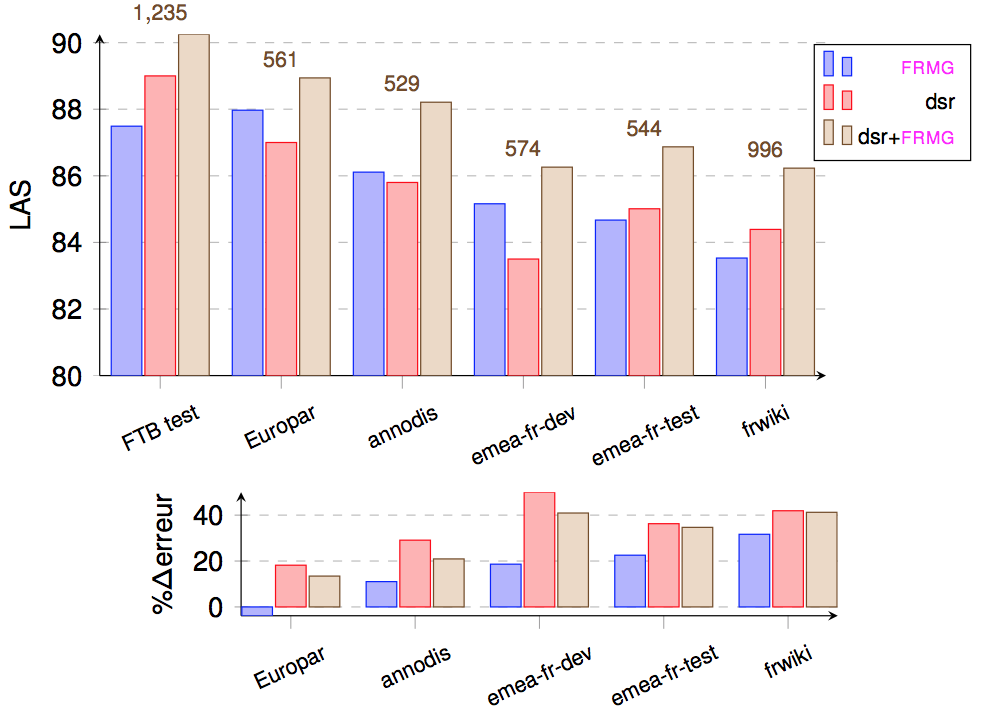
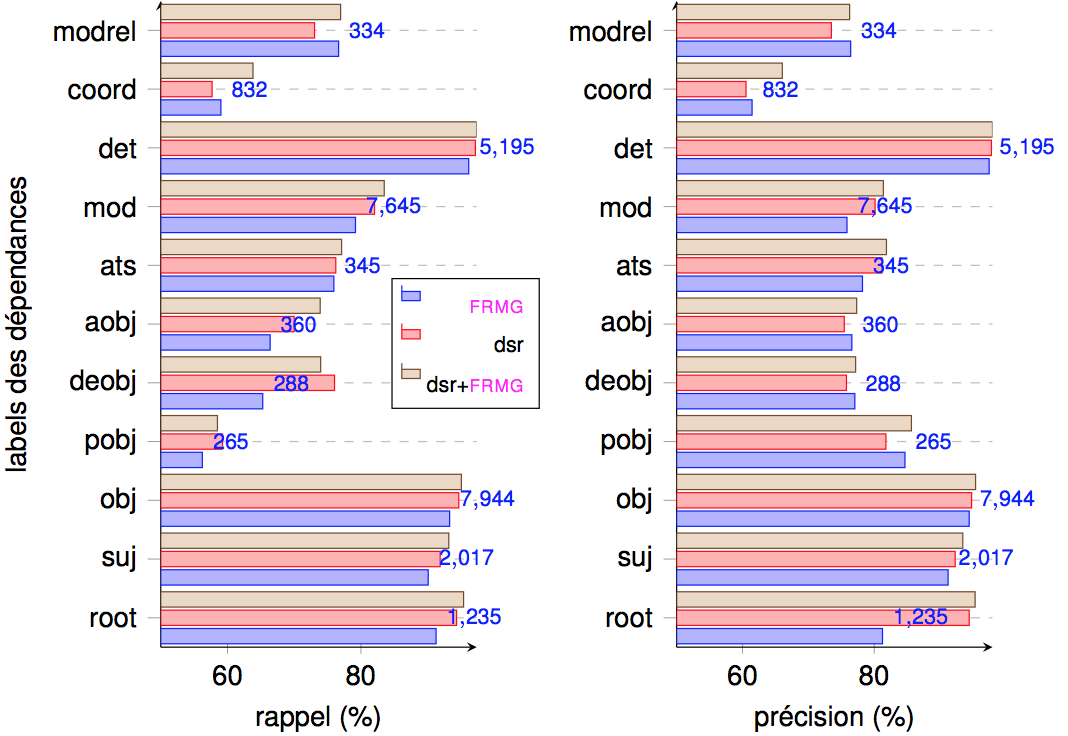
We have also conducted evaluation of FRMG, DyALog-SR, and the combined one on the heterogenous SEQUOIA TreeBank (several domains)
| FRMG | DYALOG-SR | DYALOG-SR+FRMG | DYALOG-SR +FRMG (sept. 2014) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Corpus | #sentence | LAS | delta(err) | %delta | LAS | delta(err) | %delta | LAS | delta(err) | %delta | LAS | delta(err) | %delta |
| FTB Test | 1235 | 87.49 | 89.01 | 90.25 | 90.25 | ||||||||
| Europar | 561 | 87.97 | -0.5 | -3.8 | 87.00 | +2.0 | +18.2 | 88.94 | +1.3 | +13.4 | 89.15 | +1.1 | +11.3 |
| Annodis | 529 | 86.11 | +1.4 | +11.0 | 85.80 | +3.2 | +29.1 | 88.21 | +2.0 | +20.9 | 88.45 | +1.8 | +18.4 |
| Emea-fr Dev | 574 | 85.16 | +2.3 | +18.6 | 83.50 | +5.2 | +50.0 | 86.26 | +4.0 | +40.9 | 86.41 | +3.8 | +39.4 |
| Emea-fr Test | 544 | 84.67 | +2.8 | +22.5 | 85.01 | +4.0 | +36.3 | 86.87 | +3.4 | +34.7 | 87.77 | +2.5 | +25.4 |
| FrWiki | 996 | 83.53 | +4.0 | +31.7 | 84.39 | +4.6 | +41.9 | 86.23 | +4.0 | +41.2 | 86.94 | +3.3 | +33.9 |
| Version | LAS (FTB test) | av time (s) | median time (s) | coverage (%) |
|---|---|---|---|---|
| june 2016 | 88.03 | 2.61 | 0.52 | 97.64 |
| sept 2016 | 88.06 | 0.94 | 0.29 | 97.34 |
| + lcpred | 88.00 | 0.43 | 0.17 | 97.27 |
| + lcpred + (super)tag | 88.16 | 0.28 | 0.11 | 97.20 |
FRMG and Multi Word Expressions
MWEs are a real difficulty in parsing.
The main issues are
- the lack of consensus on defining and capturing MWEs
- no closed lists or operational specification of MWEs (defining such a list was a large part of the discussions during the French parsing evaluation campaign PASSAGE!)
- a large diversity of MWE kinds: named entities, terms, locutions, idioms, ...
- a range of situation going from frozen to semi-productive MWEs
In FRMG, these diverse situations has led to a diversity of solutions, more or less perfect, at all levels, from the meta-grammar level, in the pre-parsing phases, during parsing, in the disambiguation phase, or even during conversion to some conversion schema.
Note: A large part of what is presented here may also be found in these slides presented at the AIM-West & Parseme-FR workshop (Grenoble, October 2016).
At tokenization level (SxPipe)
Many simple MWEs (such complex preps, conjunctions, adverbs) have lexical entries in Lefff and are recognized during the tokenization phase with SxPipe. However, because the recognition may be erroneous, SxPipe generally returns lattices (or DAGs) for the different readings, with and without MWEs, as shown below for "en fait" that may be interpreted as a MWE adverb or as the sequence "en" + "fait".

As illustrated by the two following sentences, both readings may be correct depending on the contex.
|
Graph
|
|
Graph
|
For a given sentence, the (untuned) disambiguation phase tends to favor MWEs when possible (through specific disamb rule).
The same mechanism also applies to Named Entities recognized by one of the components of SxPipe and that are often MWEs.
|
Graph
|
At parser level (and metagrammar level)
There exists a specific "hack" for lightverbs and predicative nouns. A notion of ncpred verbal argument is introduce at the level of the meta-grammar, with some properties, for instance to be usable without a determiner or to be modifiable by some intensifier adverbs (while keeping most of their noun properties). Lefff provides entries for so-called lightverbs (such as "faire") that have no subcategerization frames and entries for predicative nouns (such as "attention") with a frame ("to something") and the mention of the lightverb to be used ("faire"). At parsing time, when there is both the presence of a predicative nouns (such as "attention") and its expected lightverb ("faire"), the frame of the noun is transferred to the lightverb because it is acting as the tree anchor.
Concretely, the Lefff lexicon provides the following entries:
Just before parsing, the occurrence of faire in the following sentence will catch the subcategorization frame of attention (because faire is the expected lightverb for this entry of attention as an ncpred), leading to the following dependency tree (with an ncpred edge between the predicative noun and its lightverb).
|
Graph
|
Because we are using regular verbal trees for handling predicative nouns, we are more robust to all kinds of standard variations such as the use of negation, insertion of adverbs, extractions, ...
|
Graph
|
|
Graph
|
|
Graph
|
Note: there is currently around 320 entries for predicative nouns in Lefff lexicon (+ a few other added in a customization file of FRMG). There also exists other lexical files in Lefff related to polylexical verbal constructions for verb avoir.
|
Graph
|
Note: Experiments were tried in collaboration with Elsa Tolone to use the tables of the French Lexique Grammaire, in particular for predicate nouns. It was mostly OK, but efficiency problems and lower accuracy, because of the large number of entries (with no clear indication of frequent vs rare entries). More precisely, there are around 30700 entries for predicative nouns, including many like "pratiquer le yoga royal" (?)
At metagrammar level
Some locutions (or fragment of locutions) that do not really correspond to a base part-of-speech and/or that remain relatively productive (semi-frozen) are better described at the level of the meta-grammar.
For instance, one may assume that "c'est X que" or "est-ce que" is a kind of locution in French occurring in a large set of situations but with many variations (ordering, tense, negation, ...). There exists a specific class (cleft_verb) for handling "c'est que" that inherits from the verb construction with restrictions.
|
Graph
|
|
Graph
|
We have a similar case with "il y a" (as a synonym for "ago" in English) with class ilya_as_time_mod
|
Graph
|
A much more specific case is provided for the construction "X oblige" (en: X obligates), essentially found in "noblesse oblige" , but that seems to be productive:
|
Graph
|
We also found a "Fin de l'appartheid oblige, ..." in the French TreeBank
The issue with this approach is the addition of very specific constructions in the meta-grammars, leading to an increase of the number of trees in the grammar. Inheritance in the meta-grammar eases the additions of these locutions (starting from a standard verb base and adding restrictions), but that remains a tedious task and maybe not the best way to do it !
Other cases handled at meta-grammar level include (lexicalized) discontinuous constructions, such as "ni X ni Y" coordinations that may be applied on all kinds on coordinated groups
|
Graph
|
|
Graph
|
The meta-grammar also proposes quoted constructions that are interesting for some specific Named Entities, such as titles of books, movies, ... But no clear solution when these entities are not quoted !
|
Graph
|
At disambiguation level
As already mentioned, the disambiguation process tends to favor MWEs when possible.
As a special case, it is also possible to alter/complete the disamb process with a set of terms. Terms are so numerous and so domain-specific that we don't really wish to add them as lexical entries in Lefff. Most of them have also a standard underlying syntactic structure (such as "N de N") which means they can be parsed even if we don't know they are terms. However, it may be interesting for the post-parsing phase (e.g. for information extraction) to recognize them. It may also be important to recognize them as term to correctly handle some attachments. When using a list of terms, some disamb rules will favor the reading as a term and will also favor the attachment of the dependents on the head of the term.
|
Graph
|
Using a term list in the lexer will forward information to the disamb proces

The conversions issues related to output schema
FRMG provides outputs for several syntactic annotation schema, such as PASSAGE, FTB/CONLL, or the more recent Universal Dependency (UD) schema for French. Unfortunately, all these schema differ on their notion, list, and representation of MWEs. The conversion process should therefore take care, as much as possible, of these cases.
Actually, there is a simple case and a complex one:
- the simple case arises when a sequence of words for the FRMG Parser corresponds to a MWE for the output schema. Essentially, we need to forget the parse structure provided by FRMG. Of course, we are in trouble when the parse structure is not compatible with a reading as a word or a constituent, for instance when the components of the sequence belongs to distinct constuents.
- the complex case arise when a MWE for FRMG is not one for the output schema. It is then necessary to emit the expected parse structure for the MWE, but we generally have not access to this structure. Several strategies are considered. One of them consists into using rules (and default rules) providing the internal structures for large classes of MWEs. Because FRMG produces all possible analysis, another strategy consists into using one of the alternative parse not based on a MWE reading.
The following conversion rule illustrates this complex case for dates that are recognized as unitary Named Entities by FRMG but need to be expanded for UD.
|
FRMG native output
|
|
UD output
|
Some limit and complex cases
Some well identified MWEs tend to get a lexical entry in Lefff, but may be the trace of some more productive construction. As a result, we get several distinct parses that actually corresponds to a same syntactic phenomena !
For instance, we have the case of "beaucoup de" ou "peu de" that are listed as determiners in Lefff, but may also be seen as the combination of a predet with the prep de.
|
Graph
|
|
Graph
|
And this notion of predet is also productive for other constructions
|
Graph
|
|
Graph
|
Another similar case is given by "il y a" that is so common that it has an entry in Lefff as a preposition.
|
Graph
|
|
Graph
|
The productivity of some construction related to the fact they denote unusual part-of-speech may be a problem. Among the MWEs that not yet handled by Sxpipe and FRMG, we have expressions like "je ne sais" like in "il est venu je ne sais comment" or "il a pris je ne sais quel livre", with many variations "on ne sait", "nous ne savons", ... We also have the expression "n'importe qu" as in "il fait n'importe quoi", "il travaille n'importe comment", "n'importe quel élève te le dira".
|
Graph
|
A few pists for discussions
Over the years, FRMG has shown the validity of the approach of meta-grammars, being
- a large coverage grammatical resource for French, while staying manageable and extendable (sometimes difficult to tell the truth!)
- competitive with statistical parsers in terms of accuracy
- efficient enough to be used on large corpora (such as French Wikipedia) for large scale applications (information extraction, terminology extractions, knowledge acquisition, ...)
FRMG has also shown the possibility to hybrid symbolic approaches with data-driven ones by
- using annotated tree-banks to tune its disambiguation phase
- stacking with DyALog-SR, a statistical transition-based parser (with best results for French in 2014)
Several aspects of meta-grammars would still be interesting to discuss:
- even better ways to develop and maintain a large coverage meta-grammar
- how to start a meta-grammar for a new language
- re-using meta-grammar components (hierarchy, classes)
- exploring new target formalisms and/or richer ones (semantic info)
- exploring meta-grammar extraction or parametrizing from a Tree Bank
Also:
- using collaborative approaches (such as wiki) for designing linguistic resources
(mgwiki used for Sequoia Annotation Guidelines) UD guidelines